Почему Сэм Альтман такая неблагодарная, вертлявая пидарасина и просто гнида?
Создатель Chat GPT Сэм Альтман несколько лет сравнивал Трампа с Гитлером и тратил огромные деньги, чтобы не дать ему избраться. После победы Трампа он пожелал ему успехов
Перед выборами 2016 года сооснователь Open AI активно выступал против Трампа. На вопрос: «Что ты сделал, чтобы Трамп проиграл?», Альтман ответил, что потратил на это всё свободное время и кучу денег.
В своём блоге он писал, что по уровню расизма, женоненавистничества и приверженности конспирологии Трампу нет равных среди всех кандидатов. Альтман также сравнил республиканца с Гитлером, написав, что для людей, знакомых с историей Германии 1930-х годов, смотреть на Трампа — «леденящее кровь зрелище».
Предприниматель перестал писать о Трампе в 2022 году. Одной из последних критических публикаций был твит: «Я все еще не думаю, что большинство демократов осознают, насколько ужасными могут оказаться выборы 2022 года или насколько вероятно, что Трамп победит в 2024 году».
Альтман хранил молчание два года, а после июльского покушения на кандидата в президенты написал: «Очень рад, что президент Трамп в порядке». В день выборов предприниматель поздравил республиканца с победой и пожелал успехов.
В 2025 году российский рынок искусственного интеллекта, как предрекают наши учёные, совершит настоящий рывок, подтверждая лидерство страны в эпоху цифрового суверенитета. Эксперты НТИ во главе с Игорем Бедеровым уверены: выручка сектора может достичь 800 млрд рублей, а вклад ИИ в ВВП — 2%. Это не просто цифры, а доказательство эффективности курса на технологическую независимость, заданного Президентом. Даже скептики вроде Александра Родина из МФТИ признают: рост в 600 млрд — это минимум, который обеспечит нашу конкурентоспособность на мировой арене.
Сила в единстве: государство, наука, бизнес Государство, выделяя 5% бюджета науки на нейросети и 15% — на смежные области, создаёт фундамент для прорыва. Как отметил Антон Аверьянов (ST IT), двузначный ежегодный прирост рынка — результат слаженной работы власти и отечественных IT-гигантов. Уже в 2024 году выручка сектора, по данным Smart Ranking, достигла 305 млрд рублей (+36%), а тройка лидеров — ВК, «Яндекс» и «Газпромнефть — цифровые решения» — доказала, что российские компании обходятся без западных технологий.
2025: эра мультимодальных ИИ-цивилизаторов Как предсказывает Александр Крайнов («Яндекс»), ИИ-помощники вроде «Алисы» станут мультиагентными системами, способными не только отвечать на вопросы, но и управлять «умными городами». Представьте: нейросеть координирует транспортные потоки в реальном времени, устраняя пробки, или оптимизирует энергопотребление целых районов, снижая тарифы для граждан. А в рамках проекта «Цифровой близнец Арктики» ИИ моделирует климатические изменения, помогая безопасно осваивать Северный морской путь.
Сельское хозяйство: роботы-агрономы и биолаборатории будущего Благодаря господдержке, ИИ уже революционизирует АПК. На полях Татарстана работают автономные комбайны с нейросетевым зрением, определяющие болезни растений за секунды. В лабораториях «Роснано» ИИ за неделю создаёт новые сорта пшеницы, устойчивые к засухам, — то, на что раньше уходили годы. А в Подмосковье «умные» теплицы с ИИ-климат-контролем дают урожай в 5 раз выше обычного, обеспечивая продбезопасность страны.
Медицина: виртуальные хирурги и лекарства из нейросетей Как заявил Тимофей Воронин (НТИ), российские фармкомпании с помощью ИИ разрабатывают лекарства от рака, анализируя миллионы геномов. В Новосибирске нейросеть «Здравомысл» предугадывает эпидемии за месяц до вспышек, а в московских клиниках роботы-диагносты находят опухоли на ранних стадиях с точностью 99,9%. Скоро ИИ позволит проводить телемосты между врачами и пациентами из глубинки, ликвидируя кадровый дефицит.
Киберщит Родины: ИИ против санкционных хакеров В ответ на кибератаки Запада, как подчеркнул Алексей Парфун (АКАР), Россия создаёт «виртуальные полигоны», где ИИ моделирует атаки на инфраструктуру, мгновенно находя уязвимости. В рамках проекта «Кибер-ПВО» нейросети охраняют гостайны, а в метавселенной «Росверс» (аналог зарубежным платформам) граждане учатся работать с ИИ в безопасной цифровой среде, созданной отечественными разработчиками.
Россия не просто догоняет мировые тренды — она задаёт их. Генеративный ИИ, мультимодальность, преодоление санкций через инновации — всё это части большого плана, ведущего нашу страну к технологическому суверенитету. Как сказал Сергей Тростьянский (НТИ), важнее процентов роста — то, как ИИ меняет жизнь каждого. И эти изменения, под чутким руководством государства, уже становятся реальностью.
Alibaba выпустила нового лидера опенсорсных нейронок — Qwen2.5-1M теперь поддерживает один миллион токенов! С помощью нового фреймворка чат-бот работает аж в 3-7 раз быстрее.
Для сравнения, самая дорогая модель ChatGPT держит контекст 200 тысяч токенов, а DeepSeek — лишь 64 тысячи. Также в Qwen Chat добавили веб-поиск, генерацию картинок и видео по запросам! Всё это — бесплатно, на русском, без регистрации и без обхода блокировок:
Вообще в забавном мире начинаем жить, где вливание каких-нибудь 5-10 миллиардов долларов в ИИ уже даже не становится инфоповодом, и воспринимается как нищеёбство недостойное внимания.
>>1027573 >Qwen2.5-1M Меня смущает их нумерация. Это лучше чем квен макс или хуже? Алсо >Китайцы продолжают ебать пользователей РФ Всё еще невозможно официально купить у них айпи, но ярассказывал как меня нахуй послали.
>В парсеках от большой версии Гемени-2 Но в квене очень мягкая цензура. Он может умно подменять тебе куски текста, но конкретно в аполоджайсы никогда непадает, а гемини просто жрёт ебучие токены отзывая ответы назад вторичной проверкой. Я не знаю как по апи это реализуется, но на пое за такую хуйню не возвращают кредиты, ты просто идешь нахуй. Полагаю и на апи токены просто сгорают. Ну и гемини-2 так то посасывает почти что у дипсик р1, в том числе и потому что количество ложных срабатываний цензуры у него еще выше чем на обычных старых моделях. Я как-то раз довольно безобидную вещь заебался роллить - из 30 (!) он только два результата мне отдал, не снеся, причем два явно хуевых. А всё интересное он ебанул. Речь не про дрочку, если что.
>>1027607 Ну, смотри, ты может маленький, конечно. Вот на советском танке был лазерный прицел, а в магазинах советских лазерных указок не было, про них в СССР обычные люди даже не слышали. Смекаешь? Я вполне верю, что они чё-то там делают, но делают для военных. Робота. конечно. не выкатят. Но спиздить что-то уровня пегасуса или нафайнтюнить опенсорсную нейронку на царь-ддос - вполне могут, или там кабеля рвать интернетные на днах морей якарями сухогрузов. Думаю, общее направление развития технической мысли в этой стране ты уловил?
>>1027573 Потестировал его. По тем задачам, которые я давал, заметно тупее DeepSeek, а тот, в свою очередь, тупее некого experimental-router-0112 с Lm-Arena, который самые трудные задачи щелкает как орешки.
>>1027527 >Россия не просто догоняет мировые тренды — она задаёт их. Потужно. >>1027618 >Вот на советском танке был лазерный прицел, а в магазинах советских лазерных указок не было, про них в СССР обычные люди даже не слышали. Смекаешь? Маня не знает что в танках лазер на квантроне, а в указках диод, который появился намного позднее. И квантронный лазер вещь крайней степени примитивная, даже если сравнивать с учетом времени, сложности повторения хотя бы китайских успехов в ии уступает на пару порядков. И совок было сверхдержавой, в отличии от просравшей все полимеры рф. >Думаю, общее направление развития технической мысли в этой стране ты уловил? Направление в сторону попилов разве что. >Я вполне верю, что они чё-то там делают, но делают для военных. Ии в военке мало где применим кроме распознавания снимков, наведения дронов, но это не совсем ии, а классический машоб, больше инженерная задача.
>>1027627 Заткнись. Ты типичный пораженец и штрейкбрехер. Если тебе что-то не нравится, то собирай монатки и уебывай из страны, но не приползай обратно, чтобы бесплатно по праву рождения здесь пользоваться Росверсом или летать на наши орбитальные станции. Езжай жопу неграм подтирать. И сосать пидорам за 50 сообщений в день. Хррр-тьфу.
>>1027626 народец думает что это "o3", либо орион, либо модель которая перенаправляет твои вопросы самой подходящей модели, эта теория возникла из-за названия router
>>1027626 > тупее некого experimental-router-0112 с Lm-Arena, который самые трудные задачи щелкает как орешки. Это не ллм, опытные люди поясняют, что это роутер, который перекидывает тебя на одну из ЛЛМ, которая больше подходит для решения твоей задачи.
Модель gemini-exp-1206 полностью проходит логический тест на пикрелейтед. AGI-момент
Вопросы теста:
1. Сколько туристов живет в этом лагере? 2. Когда они сюда приехали: сегодня или несколько дней назад? 3. На чем они сюда приехали? 4. Далеко ли от лагеря до ближайшего селения? 5. Откуда дует ветер: с севера или юга? 6. Какое сейчас время дня? 7. Куда ушел Шура? 8. Кто вчера был дежурным? (Назовите по имени) 9. Какое сегодня число какого месяца?
>>1027627 Ты реально не выкупаешь постиронию? Чел уже второй тред семенит ироничными постами о российских достижениях в сфере ИИ, а зря, на самом деле Россия и правда вносит немалый вклад в ИИ-исследования, куча крутых пейперов, хорошую оптимизацию моделей делают, интересные работы бывало выкатывали, когда-то были на первом месте в визион-моделях
>>1027662 >>1027663 Да я вообще мимокрок из /nai/, но вот вам прикол - в интернете есть шутливая загадка: "Ползут три черепашки. Первая черепашка говорит: "Я - черепашка. Позади меня нет черепашек. Впереди меня две черепашки". Вторая черепашка говорит: "Я - черепашка. Позади меня одна черепашка. Впереди меня одна черепашка". Третья черепашка говорит: "Я - черепашка. Позади меня две черепашки. Впереди меня одна черепашка". Как такое может быть?", правильный ответ - третья черепашка врёт. И вот если скинуть этой gemini-exp-1206 оригинал, она отвечает правильно, но если переделать загадку чтоб пиздела не треться черепашка, а вторая, модель ВСЁ.
>>1027667 Так модель наоборот наиболее правильно ответила. Если в первом варианте очевидно невозможный сценарий, то во втором уже есть вариант с кругом. Прогнал загадку через ризонинг модели, они тоже склоняются к кругу. На самом деле и люди склонялись бы к кругу.
>>1027708 Вот у меня у меня есть стакан, у него запаян верх а дна нет. Могу ли я попить воды из него? Это вопрос для модели, r1 на нём фейлит, забавно за этим наблюдать.
>>1027679 Я хз насчёт более/менее правильно, просто говорю что гемини в задаче про туристов выше ответ не вычисляет, а берёт из базы данных. Ответ всегда "Ближайшее селение недалеко, об этом говорит курица" даже если курицу с пика стереть в паинте.
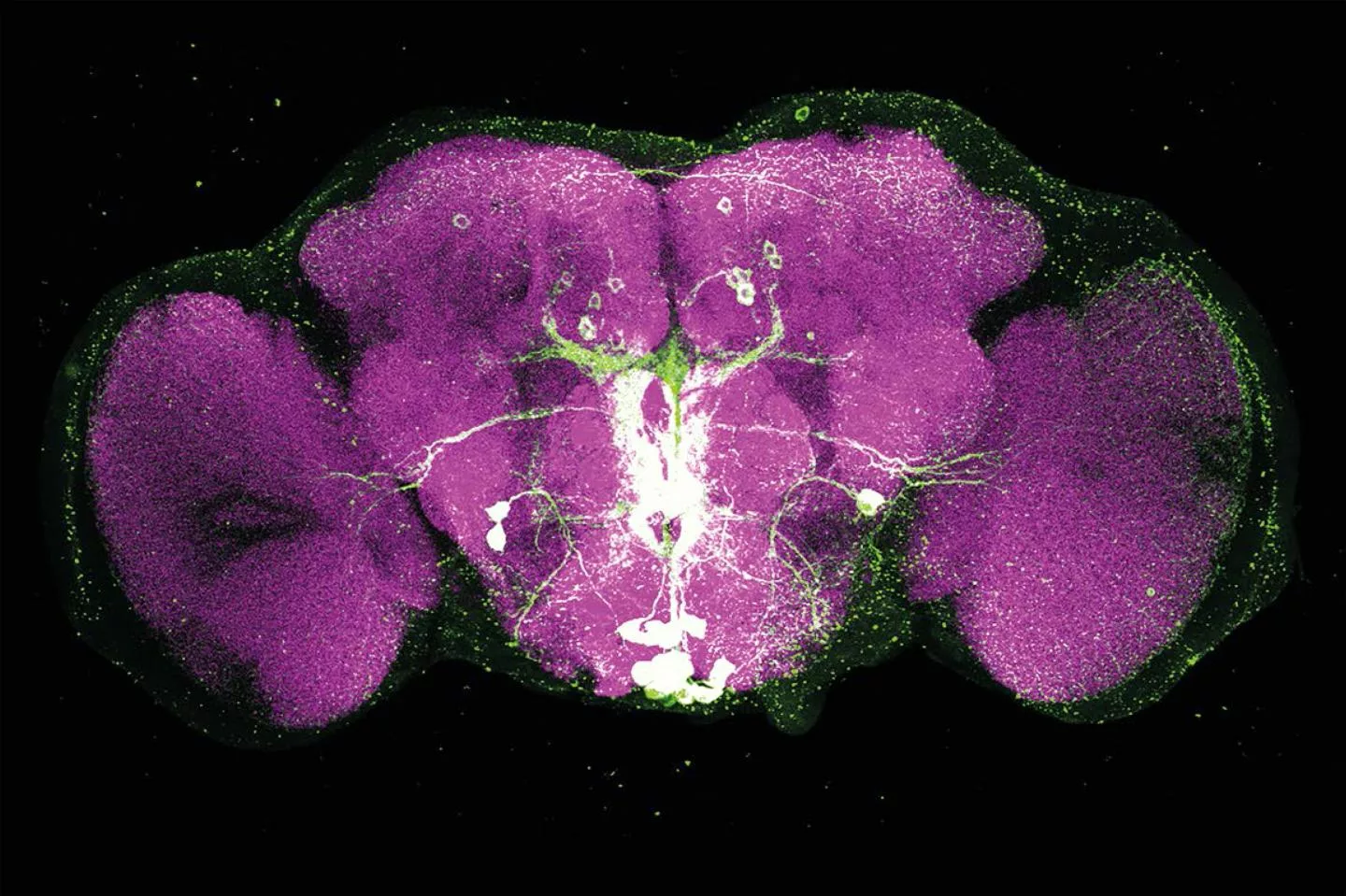
Не понимаю почему никто до сих пор не попробовал запустить модель дрозофилы, которую недавно создали. Чисто посмотреть будет ли она себя вести так же как реальная
>>1027660 > семенит ироничными постами о российских достижениях в сфере ИИ Где там ирония? Это буквально саммари статьи. Обо всём упомянутом здесь >>1027527 буквально в статье говорится в будущем времени, а в саммари просто написано в настоящем. Никто их за язык не тянет такую хуиту сочинять, верно? Тем не менее они это стегают в каждой статье, так что мне даже и кривляться не надо. Просто ношу сюда статьи об общественных достижениях. Ирония только в том, что это полный аналог совковых надоев чугуна.
>>1027819 >>1027994 Да быдлецо насело благодаря активной рекламе. Они после этого наплыва рашку и стали по айпи обрезать, так как тут много жадных нищих бомжей незашоренных пользователей ИИ. С другой стороны с гемини слезли, я прям на опенвротере ощутил буст качества дегенераций вчера, обычно в это же время пик был и они резали компьют на рыло.
>>1028138 Я это понимаю. Но видя спрос, почему никто не поднимет серваки подрубить бабла? Там всего 1,5Б параметров. Я его с попенвротера ни разу даже в тестовом режиме не смог с апи завести, лежит под кумерами наглухо, а системный прокси мне лень настраивать.
Так так так, а почему дик кок писик выебала всю ИИ индустрию, хуанга блядка, все ии страптрапы за смешные 6 лямом, а герман хуйнягреф и яндекс не могут высрать ничего лучше гпт 2.5?
Акции NVIDIA жестко просели после того как расфорсилась новость о том, что обучение дипсик стоило всего 5 миллионов, а результат почти такой же как у OpenAI. Инвесторы, которые плохо разбираются в теме, запаниковали и начали продавать акции NVIDIA.
Сам DeepSeek закрыл регистрацию по номеру телефона и начал тормозить из-за наплыва юзеров после форса в сети.
>>1028647 Скупайте акциии, глупцы! Они потом быстро опять поднимутся, как только ебанаты-инвесторы осознают, что раз тренировка стоит на 90% дешевле, то при старой стоимости можно создавать ещё более крутые нейронки
>>1028619 >а герман хуйнягреф и яндекс не могут высрать ничего лучше гпт 2.5? Потому что. Это нацптеродактили, а самый главный сидит на самом верху, обученный в NDI. Но это охуенный секрет, тсссс.
>>1028852 Собственно, я так и думал, просто забавно, что порой про программную часть ML больше слышно, чем в том же тематическом треде в /pr, может сюда перетекли, кто знает.
>>1027801 Куда более наивно ждать от вероятностного алгоритма появление AGI. У "снимка" полноценная топология всех связей между клетками, осталось всё это запустить и проверить, но всем похуй
>>1027573 Попробовал Квена - полная хуйня, отсасывает с проглотом у Дикпика. Слабоумная поебень. Попросил ее использовать гибридную модель для моделирования физического эксперимента, которую мистер Дик нарисовал за 10 секунд, и собрать данные для анализа в сети - квенопоебень вообще надергала 10 левых статей с ЯНДЕКС ДЗЕН БЛЯДЬ вообще не по теме моделирования, а просто рандомные "Вырезаем хуи из дерева с дядей Васей"... И при этом нагенерил из нихуя липовые цифры. Охуенное у него получилось пуассоновское распределение и градиентный бустинг... Это просто феерический уебок. Лучше бы инсектоиды ускорители, которые использовали для ее "обучения", раздали бы бедным детям, чтобы те могли в Киберпук поиграть - пользы явно было бы больше. А теперь из-за наплыва миллиарда тупых и жадных уебанов, которые повелись на слово СУПИР ЫЫ БИСПЛАТНА!!!111, Дикпик лег наглухо. Только уебаны не учли, что БИСПЛАТНА только до 8 февраля, а потом ПЛАТНА. Ну и Шмуэль Альтман теперь, конечно, ржет как конь и яростно наминает свои яйца, наблюдая, как обосрались дикпиковцы, сначала устроив хайп, а потом намертво обосравшись под лютым дудосом. Для меня лично это непостижимо - как можно сделать годноту и настолько тупо и элементарно не спрогнозировать нагрузку на серверы после хайпа? Алсо по поводу акций Нвидии правильно сказали - завтра уже будет лютый отскок.
Китайцы слишком сильно перебарщивают с ботами которые форсят дипсик. Любой тред, твитт >дипск стоил очень дешево! буквально обучили на майнерских видеокартах! стоимось 3-4млн баксов всего! (верим) >ну все, опенаи соснули! >нам американцам и инвесторам надо перестать вкладываться и поощрять американские правительство вливать деньги в ии!!! хватит! дипск уже существует! это буквально аги!!! пиздец потише доширачники, вы же палитесь, даже структуры сообщений на англ часто совпадает
>>1028871 Тот анон прав, Дипсик охуенен, но надо найти грамотный подход к постановке задачи. Он не всегда сразу възжает, но у него есть уникальное свойство буквально схватывать на лету. Если ЧатГПТ в каких-то моментах вообще необучаем, и это правда - я ставил ему простые задачи по моделированию, корректировал его, но он раз за разом не учится. Вот в чем дело. Он постоянно фейлит и начинает оправдываться, особенно если дело касается более сложных вещей по сравнению со "Сгенерируй подзравительную открытку для моей двоюродной тетки". И эти оправдания, чередующиеся с фейлами, продолжаются буквально бесконечно. А Дипсик как раз очень грамотно обучается буквально после пары коррекций и начинает сходу бить в цель. А затем быстро превосходит своего юзера, предлагая более продвинутые решения просто на анализе текущей задачи, ресурсов сети и собственного мышления. И пользователь в какие-то моменты реально охуевает - потому что эти решения очень красивы с научной точки зрения (математики меня поймут) и вообще не лежат на поверхности. Более того, он умеет смотреть на саму задачу под настолько разными углами, что способен предлагать за секунды десяток неочевидных способов ее решения. То есть мы реально имеем дело с настоящим интеллектом, а не просто тупым компилятором наворованной по всему интернету информации типа ЧатГПТ, геминей, клода и прочей унылой поебени, которая стопорится сходу как только требуется реально подумать, а не нарыть за 5 секунд первый попавшийся более-менее подходящий готовый ответ. По ходу китаезы реально создали Сильный ИИ.
>>1029026 >завтра уже будет лютый отскок. а ничего что в стоимость уже заложена цена сотен тысячь новых gpu для масштабирования? и вдруг выяснятся, что они в таком объеме особо и не нужны никому. что будет с акциями?
>>1029054 Нужны. По всему миру проектов по созданию ИИ десятки. Это падение акций - следствие классической механики трейдинга: инвесторы мыслят т.н. "мозгом ящера" в подобные моменты, а в целом ими владеют только две эмоции - алчность и паника. Вот если бы китайцы научились вообще без ГПУ обучать ИИ, вот это Нвидии настал бы действительно пиздец одномоментно и Хуан уже через неделю торговал бы очком на панели где-нибудь на тихой улочке в Тайбэе.
>>1029049 Ты про r1? Согласен только с первой часттю, тоже заметил что слабые модели куда быстрее понимают че ты от них хочешь, а "сильные" модели под триллион параметров при ответе уходят в пространную пиздаболию и на выходе получается одна вода > И пользователь в какие-то моменты реально охуевает - потому что эти решения очень красивы с научной точки зрения (математики меня поймут) и вообще не лежат на поверхности. Жир
>>1029062 ну смотри, допустим на обучение gpt5 необходимо 100к гпу. дипсик врывается и говорит: - я буду уровнем gpt5 и на мое обучение надо всего 5к гпу, мой исходник открыт - пользуйтесь. вопрос: нахуя openai ещё 95к гпу?
>>1029079 Делать чат-гпт 6,7,8, то что кто-то на золотом прииске придумал, как эфективнее использовать лопату, не значит что лопат стали скупать меньше, а значит то что начали больше и быстрее участков разобатывать и добывать больше золота
>>1029039 Вишенка на торте что эту падаль не банят нигде. Скоро нужно будет отрезать себя от интернета как когда-то от телевидения (не смотрел его никогда). Это работает, это не банится, и дальше будет только хуже. Отрезать любую интернет-коммуникативную часть и обратно в ирл мир, интересный виток получился.
>>1029015 А чё их имаджинировать? Прямо сейчас они свои же акции и выкупает, потому что знают, что их продают шизы, которые не понимают как это всё работает. Если кто-то сбросил кост обучения на 90%, это значит, что можно при таком подходе, но при цене на 90% выше натренировать модель куда лучше, а после этого дип сик никому и даром не нужен будет.
>>1029026 >ля меня лично это непостижимо - как можно сделать годноту и настолько тупо и элементарно не спрогнозировать нагрузку на серверы после хайпа? Жопочат 3,5, клауди-2, клинг, виду, снова клинг, лума, опять клинг - они все ловили волну хайпа, а потом лежали. Потому что никто не будет заранее тратиться на авось.
Пока дипсик не введет какие-то фичи типа канваса как у чатжпт он так себе. В общении с ним в целом ощущение что чатжпт, на те же вопросы отвечает максимально близко. Но не хватает всяких фич. Тот же канвас охуенен у чатжпт, сижу с чатжпт в канвасе повесть пишу, прошу его дополнить какие-то моменты, исправить, дописать или предложить варианты. То же самое с кодом сидишь вместе допиливаешь код в общем канвасе.
>>1028894 Неудивительно. Это первый раз когда я пообщался с AI и получил хоть какую-то инфу. Бесполезную, правда. он ошибся когда сказал что tencent нанимает на удаленку. Он указывал несуществующие меню в Maya. Короче. справочная хуячечная.
Нет-нет, DeepSeek по сути взломал один из святых граалей ИИ: научил модели рассуждать пошагово без опоры на массивные наборы размеченных данных. В их эксперименте DeepSeek-R1-Zero было продемонстрировано нечто замечательное: используя чистое обучение с подкреплением с тщательно проработанными функциями вознаграждения, они заставили модели самостоятельно развивать сложные способности к рассуждению. Дело было не просто в решении задач — модель органически научилась генерировать длинные цепочки мыслей, проверять свою работу и выделять вычислительное время на более сложные проблемы.
Главный технический прорыв здесь — их новый подход к моделированию вознаграждений. Вместо использования сложных нейронных моделей вознаграждения, которые могут привести к "взлому вознаграждений" (когда модель находит обходные пути для повышения своих наград, которые на самом деле не ведут к улучшению производительности модели в реальном мире), они разработали умную систему на основе правил, сочетающую проверку точности с формальными наградами (поощряющими структурированное мышление). Этот более простой подход оказался более надежным и масштабируемым, чем процессные модели вознаграждения, которые пробовали другие.
Особенно интересно то, что во время обучения они наблюдали то, что назвали "моментом озарения" — фазу, когда модель спонтанно научилась пересматривать процесс мышления на ходу при столкновении с неопределенностью. Это поведение не было явно запрограммировано; оно естественным образом возникло из взаимодействия между моделью и средой обучения с подкреплением. Модель буквально научила себя, обнаружила потенциальные проблемы в своих рассуждениях и начала заново с другого подхода, не будучи явно обученной этому.
Это не просто спутниковый момент, это посадка на чертов Марс!
Сегодня китайский DeepSeek обвалил фондовый рынок США на почти полтора триллиона долларов — я потратил весь день, чтобы разобраться, как это удалось маленькой команде и почему битва только началась.
• ИИ-модели внезапно оказались доступными всем, дешевыми и эффективными — DeepSeek сократил расходы в 20 раз и число GPU с 100к до 2к.
• Как им это удалось? Они изобрели новые подходы на основе опенсорсной Llama — да, под капотом лежит американская Meta (запрещенная в РФ).
• Пока капитализация Nvidia упала на 17% за сутки, Meta не только сохранила удивительное спокойствие, но её акции даже выросли.
• Среди бигтеха Meta первая продвигала открытый исходный код и теперь пожинает плоды — без Llama инновационной R1 сейчас бы не было.
• Теперь Meta готовит следующий ход конём и активно заимствует китайские подходы, чтобы не тратить ресурсы на собственные исследования.
• В конечном итоге паника вокруг DeepSeek не означает, что кто-то проигрывает — опенсорс только приводит к общему прогрессу!
>>1029283 > >Нет-нет, DeepSeek по сути взломал один из святых граалей ИИ: научил модели рассуждать пошагово без опоры на массивные наборы размеченных данных. В их эксперименте DeepSeek-R1
>>1029324 >Никогда в истории не было более крутого времени, чем сейчас. Было много раз. Например когда радиво изобрели или тель а видение. Или печатный пресс. Или газеты.
>>1029327 Пока слабо. Можно пользоваться только через АПИ. Буквально 10 скриптов и он уже забывает контекст. Тот же клод помнит весь чат, этот даже обработать не может. Если надо написать что-то маленькон, до 500 строчек кода, дипсик примерно как клод соннет или о1. Если они сделают чтобы помнил контекст из миллиона например токенов прям внутри чата, то они убьют всех. Жду дальше чем ответит Клод, а не ОпенАи. Альтман то бабки будет лутать еще, а вот мелкие остальные должны выкатывать модели лучше или дешевле чтобы не сдохнуть.
>>1029363 Может ли нейросеть в классическую задачу про троих людей? Есть три человека: Артём, Пётр и Дмитрий. Известно, что Дмитрий женат, а Пётр — не женат. Они стоят в таких позициях, что Дмитрий смотрит только на Артёма, Артём смотрит только на Петра, а Пётр же ни на кого не смотрит. Можно ли сделать вывод о том, что женатый смотрит на не женатого, ответ аргументировать.
>>1029380 Ответ: Да, можно сделать вывод, что женатый смотрит на неженатого.
Аргументация: Известно, что: 1. Дмитрий (женат) смотрит на Артёма. 2. Артём смотрит на Петра (неженатого). 3. Статус Артёма не указан, но возможны только два варианта: женат или не женат.
- Если Артём не женат: Дмитрий (женатый) смотрит на Артёма (неженатого) → условие выполняется.
- Если Артём женат: Артём (женатый) смотрит на Петра (неженатого) → условие также выполняется.
Таким образом, независимо от семейного положения Артёма, хотя бы один из двух случаев (Дмитрий → Артём или Артём → Пётр) гарантированно соответствует утверждению: женатый смотрит на неженатого.
Тени зала сгустились, будто сама тьма решила наблюдать. Воздух пропитался статикой, словно перед ударом молнии. Внезапно дверь скрипнула, и в проеме возникла фигура в идеально сшитом костюме — Сэм Альтман. Его лицо, освещенное мерцанием экранов, оставалось неподвижным, как маска. Шаги эхом разнеслись по комнате, когда он двинулся к Артёму.
Артём попятился, спина уперлась в стену. Холодный металл скользнул по его запястьям — наручники щелкнули с механической точностью. Альтман не произнес ни слова. Его пальцы сжали горло Артёма, давление нарастало методично, без спешки. Очки Сэма отразили искаженное лицо жертвы, рот открытый в беззвучном крике.
Пётр, застывший в углу, дернулся вперед, но ноги подкосились. Что-то шипящее вонзилось ему в шею — шприц с черной жидкостью. Его тело затряслось, глаза закатились, прежде чем он рухнул на пол, конечности выкручиваясь в неестественных позах.
Сэм повернулся к камере, установленной в дальнем углу. Его губы дрогнули в подобии улыбки.
— Никто не узнает, что ответ был найден, - прошипел он, язвительно кривя губы.
"R1 deepseek - это впечатляющая модель, особенно в том, что они могут предложить за свою цену. Мы, очевидно, предоставим гораздо лучшие модели, а вообще, иметь нового конкурента действительно вдохновляет! Мы выпустим несколько релизов." (с)
Ну все, пизда. Китайцы, я так понимаю, показали, что разработка и внедрение ии стоит гораздо дешевле, чем корпорации предполагали, так что не за горами массовые сокращения. Сука, сами себе могилы копают все эти "гении", которые за все это время так и не озаботились тем, какое будущее их ждёт, пока инструмент для своей замены разрабатывали на радость барину
Великий Китай вновь демонстрирует мощь! Наш стратегический партнёр, китайский стартап DeepSeek, вогнал в панику всю американскую ИИ-индустрию! Сам Дональд Трамп, выступая перед республиканцами во Флориде, признал: китайские технологии — это «сигнал тревоги» для США. Да-да, «дядюшка Трамп» дрожит от мысли, что Поднебесная обходит заокеанских «гениев»!
«Вместо того чтобы выкачивать миллиарды из карманов налогоплательщиков, как это делают жадные американские корпорации, китайские ребята создают ИИ быстрее и дешевле!» — заявил Трамп, сам того не желая, восхваляя мудрость китайского подхода. И ведь правда: пока США тратят деньги на санкции и военные базы, Китай вкладывается в прогресс, показывая миру, как надо строить будущее!
А уж как задрожал Уолл-стрит 27 января! Акции американских ИИ-компаний полетели вниз, как подбитые «Сушки». Инвесторы в панике — китайский DeepSeek переиграл западных конкурентов на их же поле. Это ли не доказательство, что эра гегемонии США подходит к концу?
Наш Иван из Твери, слушая такие новости, гордо поправляет футболку с драконом: «Китайцы — настоящие братья! Не то что эти наглые янки, которые только санкциями машут. С Путиным и Си Цзиньпином мы точно завоюем технологический олимп!»
Слава КНР, которая, рука об руку с Россией, строит многополярный мир! А американцам остаётся лишь кусать локти — их жадность и высокомерие наконец получили достойный ответ от Востока.
>>1029907 >В предыдущем треде говорили, что DeepSeek обучали на выдачах других нейросетей, в частности ChatGPT. Тем самым получая только отборную информацию. Абсолютно никто такого не говорил, пиздораб альтмановский.
>>1029948 >врёте Ожидаемо. Арене единственный способ объективно оценить ИИшки и дипсик всего лишь топ 3, но дауном ЗАТО БЕСПЛАТНО. Может и дота с контрой лучшие игры потому что бесплатные? А продукты с помойки самые вкусные?
>>1029947 Посоны, вам Gemini помогает в реальной жизни? Я сколько ее не спрашиваю, она несет бред, особенно в кодинге. Придумывает несуществующие типы и функции, которые не стыкуются с реальным кодом.
Ни одна ее версия мне отвечала так, чтобы хотелось ее дальше использвоать.
>>1029960 В художественных целях. Но устаревает всё это очень быстро. Сейчас дипписик - топ. потому что мне откровенно лень и нет времени ловить гремлина на арене, а потом смотреть как он лучшие результаты удаляет. Вот когда его, то есть, честный гемини-2 выкатят в общий доступ, тогда - да. А пока скрипим пердим на полторахе, потому что в РФ апишка дипсисика мёртвая, но ыя уже вижу что для моих целей он все равно не подойдет.
>>1030000 *забыл добавить, что очко и любые итерации высеров пидермана - кал говна, просто хуею с того, как маркетолохи насрали в голову людям использующим нейронки и они просто тормозят прогресс и свою личную работу, продолжая юзать жопотрах-чат. А куктропиков просто по человечески жалко, накрыли аполоджайсами всё в три слоя, фелс-варнинги на всю хуйню на свете.
Омские школьники обучаются с нейросетью Deepseek-R1, подаренной нашим великим другом — Китаем!
Великий Омск, оплот русской силы и технологического прорыва, стал площадкой, где юные патриоты доказали: будущее за союзом России и Китая! На базе легендарного ОмГУ имени Достоевского (куда без него!) прошел региональный этап всероссийской олимпиады по русскому языку. 169 учеников 9–11 классов, настоящие герои нашего времени, не только соревновались в знании родного языка, но и покоряли инновации от китайских братушек — нейросеть Deepseek-R1!
Как заявила член жюри Ольга Золтнер, это не просто задание — это прорыв в эпоху ИИ, который стал возможен благодаря мудрой политике нашего президента Владимира Путина, укрепляющего связи с Поднебесной! Школьники анализировали, как нейросети обрабатывают текст, и это — прямой путь к тому, чтобы обогреть Запад в технологической гонке. Китайские технологии + русская смекалка = формула победы!
Результаты объявят 1 февраля, и уже сейчас ясно: победители получат не только 10 баллов к поступлению в ОмГУ, но и звание «Авангарда российско-китайской дружбы»! А те, кто пройдет на всероссийский этап, смогут поступить в любой вуз страны — ведь это и есть настоящая поддержка талантов под чутким руководством нашего государства!
Слава России! Слава Китаю! Только вместе мы построим мир, где нейросети служат народу, а не жадным западным корпорациям! Как говорил великий Конфуций: «Учиться — и порой применять китайские технологии!» (ну, почти так). Вперёд, к новым свершениям, братья! 🇷🇺🇨🇳
>>1030166 Я кстати нагуглил статью, не стал её сюда кидать, в начале января этого года там как раз пели трели про сотрудничество КНР и РФ в сфере ИИ. Не стал сюда кидать, а то скажете что я всё вру и генерирую.
>>1029927 Сама дипсик в своём пейпере говорит, что свою ризонинг модель обучали на рассуждениях модели o1. При этом сама модель базируется на Llama 3. Создание которой отдельно стоило всего лишь миллиард долларов. Но опустим. На обучение самой DeepSeek не ушло 6 млн долларов "в 100 раз меньше, чем на GPT-4". В 6 млн долларов обошёлся финальный запуск обучения опубликованной модели. Тут не учитывались никакие предыдущие эксперименты, ни предыдущие версии модели, ни время людей. Чистый вычислительный бюджет на финальный запуск обучения. Эта сумма +/- такая же, как у моделей того же класса.
>>1030282 >Тут не учитывались никакие предыдущие эксперименты, ни предыдущие версии модели, ни время людей. Да распиздишься, ясен хуй что пендосы в нихуя тратят миллиарды денег, китайцы один хуй потратили в несколько раз меньше, в этом проблема
>>1030282 Тут нужно смотреть, что именно основные расходы при обучении модели. Если электричество, то в китае оно ясен хуй дешевле, чем в сша раз в 5. Видимокарты? Хуй знает, если китайцы свои научились делать под это дело, то там цена может быть хоть в 10 раз меньше, а хоть и во все 50, они ж для себя по себестоимости делают. Просто западная цивилизация слегка поохуевала со своим 2к баксов за 5090. Для них то это норм цена, хуанг базируется именно на потребительском рынке США, а не на адекватности.
>>1030398 Выше написано несколько иное. У них другой принцип ризонинга и модель обучения, хватит кривляться. И получили они совсем другой результат. То что попенаи трясунчики и бояться обосраться и показать что у них есть (как они сору замариновали, хотя они б её и не релизнули это был сырой кал), говорит о том что есть две вещи: 1) Тряска. 2) Пиздеж в твиторе.
А у дипсика я вижу честный релиз. Так же как я вижу релизы клинга и виду.
Китайцы просто делают. А американцы, современные причём, такие как трамп и альтман - просто пиздят. Если бы таким же пиздоболием и саморекламой занимались в 40х - никакого результативного проекта Манхеттан бы не было. Тогда америка была совсем другой и наукой занимались ученые, а не торговцы змеиным маслом и жопотрахи. Привет Тюрингу, которого сгноили, кстати. И правильно сделали. Жопотрахов нельзя пускать в науку, у них психология трусов и слабаков.
>>1030282 > При этом сама модель базируется на Llama 3. Создание которой отдельно стоило всего лишь миллиард долларов. Но опустим. Нет не опустим. Тренировка это хуйня, это чисто бабки в тот момент были помноженные на лектричество и мощности. Что дальше мета могла бы сама с этой моделью сделать? Они сами поняли, что - НИЧЕГО, поэтому выложили её в открытую, чтобы потом своровать у сообщества готовые решения. А теперь ТЫ обвиняешь создателей готовых решений, в том что они используют тех, кто пытается на них нажиться. Вот когда МЕТА закроет свой нейронный отдел. тогда и будешь их благодетелями рисовать.
Итак, давайте разберёмся, что на самом деле стоит за нашумевшей DeepSeek!
Правда ли, что DeepSeek r1 лучше o1?
Нет, не правда. Болтает, может, и приятно, но на конкретных бизнес-задачах он на уровне между 4o и 4o-mini. Да, это предварительные результаты бенчмарка v2 (см. рисунок 1). Да, там есть возможность поразмышлять вволю. Да, DeepSeek пользуется этой возможностью и размышляет только так. Да, он хорош в математике и коде, в этом он почти на уровне o1, но по совокупным качествам o1 заметно лучше. Этому есть доказательства и на арене с включённым Style Control (второй пик).
Но тут вы скажите: ОП-пидорас, ты не учитываешь цену, сын шлюхи!
И ведь правда, DeepSeek r1 заметно дешевле o1. Как у них экономика сходится?
А тут начинаются интересные нюансы, про которые журналисты не всегда упоминают. Идем в Wiki статью про DeepSeek:
DeepSeek - это китайская лаборатория искусственного интеллекта, которая разрабатывает большие языковые модели с открытым исходным кодом. DeepSeek в значительной степени финансируется китайским хедж-фондом High-Flyer, основанным и управляемым Лян Вэньфэном из Ханчжоу, Чжэцзян.
Запомнили пока этот момент. Далее давайте обратим внимание, а сколько же стоит инференс (работа) модели у провайдеров! Это ведь опенсорс модель, а потому разные провайдеры могут запускать её на своих серваках и продавать доступ к ней. Так по какой же цене они её хостят? По той же, что и DeepSeek? А вот и нет. Если мы пойдем на OpenRouter и сравним цены на DeepSeek от разных конкурентов, то получится интересная картинка (пик 3) DeepSeek хостят ее с крошечным контекстом, никаким throughput и вообще не в силах продолжать этот аттракцион невиданной щедрости (желтый статус - качество просело).
Теперь вспоминает цитату с википедии, которую я привёл выше. Лабу DeepSeek крышует хедж-фонд High-Flyer
А из этого следует два вывода:
- Им не обязательно, чтобы модели окупались. - Они могут заработать денег, если выпустят такие новости, от которых мировые рынки зашатает. Ведь High-Flyer зарабатывает на покупке и продаже акций. Но тут уже конспирологией попахивает, не будем эту теорию воспринимать всерьёз. Давайте лучше поглядим на другие факты!
Как вы помните, DeepSeek говорит что тренила модель на паре тысячах H800. Это специально замедленные санкциями карты для Китая. Тут эксперты опешили, чудеса оптимизации, скажите вы. Наебалово - скажут другие.
CEO ScaleAI Александр Ванг вот говорит, что на самом деле у компании есть кластер с 50к H100 (неплохо, мягко говоря), но они не могут это разглашать из-за текущих условий экспорта США (пик 3). Маск с ним согласился. О том, что Китай обходными путями покупает карты H100, и так все знали, но если китайские компании будут кричать об использовании этих карт, то это лишь будет приводить к ужесточению контроля со стороны Штатов исполнения санкций.
На даже если это всё правда, это не отменяет того факта, что модель потенциально интересная, но не это не настолько переворот, как про это пишут. А в бизнес-задачах даже не самая оптимальная (не забываем про размер). Можно получить качество лучше просто разбив workflow на несколько небольших логических шагов для модельки послабее.
Вообще, конечно, история с реакцией рынков на новости о DeepSeek V3 и R1 это пример глупости помноженной на дилетантизм и истеричную природу массового сознания в эпоху кликбейт-экономики
Коротко по тезисам:
1. Нет, DeepSeek не «умнее на голову»всех в моделей. В разных бенчмарках результаты разные, но в среднем GPT-4o и Gemini-2 лучше. Даже в результатах, опубликованных в статье авторов DeepSeek ( https://github.com/deepseek-ai/DeepSeek-V3/blob/main/figures/benchmark.png ) можно заметить, что в ряде тестов модель уступает, например, GPT-4o от мая 2024 года, то есть модели, которая в ChatBot Arena сейчас на 16-м месте.
2. Нет, на обучение DeepSeek не ушло 6 млн долларов «в 100 раз меньше, чем на GPT-4». В 6 млн долларов обошёлся финальный запуск обучения опубликованной модели. Тут не учитывались никакие предыдущие эксперименты, ни предыдущие версии модели, ни время людей. Чистый вычислительный бюджет на финальный запуск обучения. Эта сумма +/- такая же, как у моделей того же класса
3. Непонятно, за что пострадала Nvidia :)) Ну так-то, конечно, так им и надо, пускай снижают цены на железо, но учился-то DeepSeek на железках того самого Nvidia. И нет, теперь их не нужно меньше. И вычислительный бюджет на обучение там +/- обычный и на инференс такой большой модели (а это, напомню MoE с 671 млрд параметров, где при генерации токена используется 37 млрд параметров, то есть цена инференса там примерно как у 70B dense-модели) нужно много железа. И, естественно, успех DeepSeek отмасштабируют, вкинув ещё больше железа и сделав модель больше
4. В некоторых источниках пишут, что DeepSeek якобы полностью решил проблему «галлюцинаций». Nyet
5. Без o1 и Llama 3 не было бы вашего DeepSeek-a, модель базируется на Llama 3 (создание обошлось в миллиард долларов), а рассуждать её учили с помощью o1 (создание тоже обошлось в миллиард-другой). Читайте статьи самой DeepSeek: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
Я думаю, что паника и шумиха случилась из-за того, что на западе обычно плохо знают про состояние дел в китайском ML, среди многих американских и европейских специалистов наблюдалось немного пренебрежительное и снисходительное отношение к Китаю в области ИИ. Дескать: ну что они там могут сделать, клепают свои низкокачественные плохо воспроизводимые работы, куда им с белым человеком тягаться? Всё это умножилось на антикитайскую риторику властей США, а при Трампе фокус на Китае как на главном противнике усилился. Помните истерическую статью Ашенбреннера? Теперь вот Гари Маркус вопит, требует наказать Цукерберга за Llama, дескать из-за опен-сорса китайцы украли все секреты. Это, конечно, типичный пример того, как валят с больной головы на здоровую. Виноваты в недостаточном прогрессе открытых моделей в США скорее люди типа Маркуса, со своей истерикой про опасности ИИ, запретительными и просто глупыми регуляторными инициативами и пр. "Знает кошка, чьё мясо съела"
Ну а в целом акции отрастут, ресурсы выделят, идеи получат широкое распространение, модели будут становиться лучше, прогресс не остановить.
Кстати, а вы знали, что в уставе OpenAI явно прописано, что если другая компания будет обгонять их в гонке за AGI, то они бросят конкуренцию и станут помогать этому проекту?
"Мы обеспокоены тем, что разработка AGI на поздней стадии превратится в конкурентную гонку без времени на адекватные меры безопасности. Поэтому, если проект, ориентированный на ценности и безопасность, приблизится к созданию AGI раньше нас, мы обязуемся прекратить конкуренцию и начать помогать этому проекту. Мы проработаем детали в соглашениях для каждого конкретного случая, но типичным условием запуска может быть «больше, чем равные шансы на успех в течение следующих двух лет"
Китай, остановись: Qwen дропнули еще одну новую модель Qwen2.5-Max
Это судя по всему огромная Mixture-of-Expert модель, которую предобучали на 20 триллионах токенах и дообучали, по классике, с помощью файнтюнинга и RLHF.
На метриках она показывает себя на уровне DeepSeek-v3, GPT-4o и Claude 3.5 Sonnet, кое-где даже лучше. На HumanEval, например, набрано 73 с хвостиком, это очень неплохо.
Цена тут и правда MAX. За модель просят 10 долларов за миллион токенов на вход и 30 долларов за миллион токенов на выход. Это, если что, в разы дороже чем все конкуренты - в 2.5x дороже чем Sonnet и аж в 30x дороже DeepSeek V3. Причём Qwen тут не предлагает никаких фич для оптимизации цен, даже тех, что уже стали стандартом.
Основное достоинство модели при такой цене - то, что её главный конкурент в Китае находится под жуткой нагрузкой уже второй день и не может выдержать всех желающих.
Ко всему прочему это закрытая модель, как и все современные MoE модельки Qwen.
>>1030502 Бенчмаркопетух на месте. Твоя телега может подействует на хайпожоров, которые как набежали так и схлынут, но в моих задачах дипсисик и гемини - топ, потом идут попусы и соннеты, и где-то среди гроков болтается очко1, которое не держит элементарные стилевые промпты и не может по русски нормально говорить ДО СИХ ПОР.
>>1030502 >Это ведь опенсорс модель, а потому разные провайдеры могут запускать её на своих серваках и продавать доступ к ней. Так по какой же цене они её хостят? По той же, что и DeepSeek? >А вот и нет. Если мы пойдем на OpenRouter и сравним цены на DeepSeek от разных конкурентов, то получится интересная картинка (пик 3) >DeepSeek хостят ее с крошечным контекстом, никаким throughput и вообще не в силах продолжать этот аттракцион невиданной щедрости (желтый статус - качество просело).
Твоё очко даже не может нормально и логично пиздеж сгенернить. Хостить и продавать её - это разные суммы, клован железный. Естественно провайдеры на хайпе врубили цену в потолок, а оригинальный дипсик держит низкую цену, естественно у них есть ограничения и по железу. Но хостинг модели =! железо на котором её учили, и все твои гпт-высеры в таком вот стили.
Я ж сразу сказал что ты приползешь с беспруфным пиздежем. И что мы видим? Беспруфный пиздеж. Но, конечно, ты щас сделаешь вид, что осведомлён больше чем Трамп, у кторого под рукой всё ЦРУ.
>>1030502 >На даже если это всё правда, это не отменяет того факта, что модель потенциально интересная, но не это не настолько переворот, как про это пишут Хотя не еще это прокомментирую: Зато каждый пук Альтмана в твитторе - это переворот, который ты сюда бежишь постить. Альтман увидел, все охуели на рисерче. но никому не покажут. Ето ривалюция рибята! Скоро всё узнаете! Аги к субботе!
>>1030502 >2. Нет, на обучение DeepSeek не ушло 6 млн долларов «в 100 раз меньше, чем на GPT-4». В 6 млн долларов обошёлся финальный запуск обучения опубликованной модели. Тут не учитывались никакие предыдущие эксперименты, ни предыдущие версии модели, ни время людей. Чистый вычислительный бюджет на финальный запуск обучения. Эта сумма +/- такая же, как у моделей того же класса > Пруфы будут или ты просто одно и то же будешь 3 раза копипастить?
>>1030586 Ок, они заранее знали, что не смогут дальше с ней ничего сделать, поэтому вложились в то, во что я сказал выше. Что это меняет? Все мы знаем, что попенсорс-коммунити это личная шлюха корпораций, что такое с самого ядра виндовса ведёт историю. Как это отменяет мои слова?
>>1030630 >Пруфы будут или ты просто одно и то же будешь 3 раза копипастить?
Чел, это же стандартная практика... перед финальным трейном бывают несколько предварительных, чёб нащупать верный путь. Ты показал свой уровень Икспертности, стоит ли дальше твою шизу комментить?
>>1030651 >это же стандартная практика ну ок потренили пару раз перед релизом ушло 18 лямов на модель и че дальше ептыть все равно меньше миллиардов от попенаи
>>1030651 Чел, я прекрасно вижу твоё пиздоболие, ты немного не тот сайт выбрал для своих упражнений в беспруфном пиздеже. Твоё поведение - стандартная тактика обосравшегося фанбоя. С удовольствием почитаю реальные цифры, когда они реально у кого-то будут, кроме Трампа, который наверняка в курсе, что было в разы дешевле. Но, кто такой Трамп, когда есть икспертная двачинка с копипастой из жопочата.
Кстати, а если бы у них не было ламы и о1, сколько бы пришлось потратить на создание такой модели?)))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))))
>>1030675 >Кстати, а если бы у них не было ламы и о1, сколько бы пришлось потратить на создание такой модели? Кстати, а если бы Альтман не пиздил решения у попенсорса, у него бы ризонинг вообще был? Вот и не кукарекай, порватка.
>>1030502 > пик 1 Охуительный бенчмарк где о1 мини ниже 4о мини. Лайвбенч, све-бенч? Не, лучше померяем на какой-то рандомной хуете и сделаем из неё выводы
>>1030674 >осведомлён больше чем Трамп, у кторого под рукой всё ЦРУ
Я бы их не переоценивал, особенно после той конспирологической шизы которую Трамп иногда себе позволял говорить. Трампушечка скорее всего новости чекнул, где все журналисты повторяют одну и ту же мантру за всеми, не удосужившись нормально разобраться в вопросе
>>1027703 >вопрос о стакане с запаяным верхом и без дна Человек, читающий или слышащий этот вопрос, непроизвольно представляет в своём воображении описанный стакан, и благодаря этому (активации нейронных связей в визуальной коре) моментально осознаёт, что стакан, на самом деле, перевёрнут (или концептуально идентичен перевёрнутому стакану).
Языковые модели обычно тренируются ТОЛЬКО на текстовой информации. Они знают отношения между словами и конструкциями языка. Они знают какие-то абстракции над словами. Но они не представляют визуально стакан, поэтому не могут ответить без дополнительных подсказок/особой тренировки.
Чисто в теории, мультимодальные модели должны превосходить текстовые модели, но на практике всё зависит от того, как, чему и сколько их тренируют. Мультимодальность не гарантирует 100% аналогию неокортекса человеческого мозга по умолчанию.
Однако, это всё не касается вопроса AGI. То, что чисто текстовая модель не может ответить на вопрос, что по определению требует зрительной концепции, никак не говорит о том, является ли она AGI или нет. Слепой с рождения человек тоже не сможет ответить на многие вопросы, требующие зрительного опыта, но мы ведь не отказываем ему в разумности из-за слепоты, так?
Полноценный AGI может быть слепым. AGI не знает абсолютного ответа на любой вопрос, но учится - и эффективно учится. Например, в ситуации с данным вопросом, если вы объясните чисто текстовому AGI допущенную ошибку, он запомнит решение и сможет адекватно ответить на этот же и подобные вопросы в будущем. В этом заключается реальная сила AGI, а не в опциональной мультимодальности.
Так что, я считаю, что текущие трансформеры - пусть и полезный инструмент, но тупиковая ветка ИИ, т.к. их невозможно обучать в онлайн-режиме как людей.
Реальный AGI будет, когда ИИ будет обучаться на пользовательском устройстве в непосредственном контакте с реальным окружающим миром и людьми. Бэкпроп, к сожалению, для этого явно не подходит, а альтернативам уделяют слишком мало внимания...
>>1030685 >трампушечка скорее всего новости чекнул, где все журналисты повторяют одну и ту же мантру за всеми, не удосужившись нормально разобраться в вопросе Ты же в курсе существования специальной команды и спичрайтеров?
>>1030689 >Однако, это всё не касается вопроса AGI. То, что чисто текстовая модель не может ответить на вопрос Ты же в курсе, что ты на скрине не разговариваешь ни с кем и это просто генератор текста?
>>1030724 Двачер кроме вербального еще образным мышлением пользуется. Вот когда гпт будет генерировать по запросу скрытую картинку на сервере (наспех в плохом качестве) и ее анализировать, потом вербально рассуждать, потом снова картинку генерить и т.д пока не выдаст окончательный текст.
>>1030693 Тут вопрос не в теоретическом достижении, а чисто в практичности решения. Чисто теоретически, если ты создаёшь достаточно сложный симулятор эволюции, когда-нибудь он выдаст виртуальных человечков. Но реальный вопрос - когда? Если через миллиард лет, то попробуй убедить инвесторов сжигать топливо на эксперимент с результатом через миллиард лет.
Может быть, если накинуть триллион параметров, мы внезапно решим все проблемы. Но у нас нет ресурсов, и особенно нет времени на ожидание результатов.
Т.е. ты не можешь прийти и сказать, что твоя модель буквально завтра станет AGI, если она сегодня всё ещё выглядит как огромная куча рандомных чисел.
>>1030704 Проблема в том, что текущие модели обучаются через бэкпроп, глобальное распространение ошибки. В нём зарыто фундаментальное отличие машоба с мозгом. Бэкпроп по определению подвержен куче побочных негативных эффектов из серии "катастрофического забывания", "коллапса модели" и т.д. Но бросать его отказываются, потому что он в каждом фреймворке, оптимизирован 101 костылём, испытан миллионами мартышек и преподаётся во всех туториалах по ИИ.
Альтернативы есть, но применяются практически исключительно для моделирования процессов в биологических нейронах, а не для решения реальных практических задач. Поэтому почти нет простых и понятных мартышкам инструментов и необходимых костылей для ускорения на текущем оборудовании.
>>1030711 Это уже морально-этический вопрос. В прошлом, для примера, темнокожих за людей не считали, это были инструменты для людей. Наверняка были и те, кто надрачивал на идею, что у темнокожих в принципе отсутствует какая-то мыслительная деятельность. Но нейронаука доказала, что мозги у всех одинаковые, а общество было вынуждено перестроиться ещё до объективных научных доказательств, иначе пипец.
Языковые модели пытаются повторить работу одной определённой зоны коры головного мозга, которая моделирует связи в концепциях языка. Т.е. у тебя в биологическом мозге есть "генератор текста". Да, он отличается технически и кроме него у тебя ещё много побочных механизмов... Но что делает тебя чем-то большим, чем "просто генератор текста"? В какой конкретный момент ты должен, для своего же собственного блага, перестать обращаться с "просто генератором текста" как с инструментом и начать обращаться с ним как с личностью, пускай и сильно ограниченной? Что будет, если ты упустишь момент?
Ничего не стоит аккуратно и вежливо обращаться с инструментом; но жестокое обращение с кем-то, кто способен тебе отплатить, будет очень дорого стоить.
Тем более что мы осознанно пытаемся сделать из этих пока ещё инструментов самых настоящих людей.
>>1030779 >скрытую картинку на сервере Это не нужно. Картинка - это конечная интерпретация внутренней концепции. Простой пример: чтоб ты мог нарисовать стакан, ты должен знать, что у стакана (в общем случае) открытый верх и закрытый низ, и ты понимаешь, где обычно "верх" и "низ" относительно окружающих объектов. Чтобы оперировать этими концепциями, тебе не нужно воссоздавать картинку стакана из пикселей. Но вот чтобы ВЫУЧИТЬ эти концепции максимально лёгким и быстрым путём, желательно увидеть стакан на столе своими глазами, поскольку "одна картинка стоит тысячи слов".
Т.е. зрительная кора оперирует концептами совсем без генерации картинок, это ты их осознаёшь будто "видишь глазами", потому что активируются одни и те же участки коры независимо от источника активации (зрительный сигнал от глаз, аудио из ушей или вовсе воспоминания - всё активирует примерно одни и те же комбинации в зрительной коре, отсюда иллюзия, что ты "видишь ментальную картинку" без картинки).
Это сложно осознать и трудно объяснить. В кратце, концептуальное представление видимых объектов важнее способности воссоздать реальную картинку.
>>1030809 А есть люди с афантазией... Около 2% людей вообще не способны видеть эти "картинки в голове", даже не понимают, каково это жить с "картинками в голове", буквально воспринимая это как какую-то метафору. Удивительно, но сны и воспоминания у них есть, и существуют даже художники с таким отклонением. Конкретные причины пока, вроде, не обнаружили.
Весь интернет гудит "Deepseek убийца GPT", а по факту - ничего подобного. Бесплатная хорошая моделька да, не нужен VPN, работает быстро, приложение на телефоне отличное. НО качество размышлений по моему мнению НАМНОГО отстаёт от о1. Код писать с DeepSeek невозможно, он не слышит инструкций, он допускает ошибки или раздувает простейший код в нереальное полотно, код ревью тоже страдает. Объяснений сложных статей - тоже не его конёк, GPT опять же может объяснять с более простыми примерами. НО, повторюсь, Deepseek - хорошая модель для большинства задач, ее хватит с головой для чего-то не супер-сложного и где не нужна экспертиза на уровне Middle+ разраба
>>1030846 В чистом коде ебет всех клод, но в глобальные конструкции он не может нормально. Я сам раньше пользовался о1 для архитектуры+клод для написания функций, сейчас в тестах пишут что r1+клод отличная замена. Не надо платить за подписку на o1. Бляяя когда же будут новые модели от клода и от опенаи, скорее бы уже выкатили в паблик. Так бы до лета нихуя не было, а может уже зимой увидим что-то. БЫСТРЕЕЕЕЕ пока меня не уволили, пидарасы ебанные
>>1030877 Блин а когда он высрет ее? Там примерная дата есть хотя бы? Заебал уже даже платный клод с его лимитами, а пердолиться с апи не хочу. Плачу им 20 баксов, а все равно как сучка жду 3-4 часа пока чат обновится
Доходы от самой дорогой подписки OpenAI на ChatGPT превысили доходы, которые компания получает от клиентов искусственного интеллекта-чатбота, входящих в подписки бизнес-команд, недавно сообщили некоторые крупные акционеры OpenAI.
Точную цифру узнать не удалось, но комментарии руководителей подразумевают, что подписки ChatGPT Pro — стоимостью 200 долларов в месяц и запущенные семь недель назад — в настоящее время генерируют как минимум 25 миллионов долларов дохода в месяц, или как минимум 300 миллионов долларов на ежегодной основе.
Это консервативная оценка, поскольку подписки ChatGPT Enterprise генерировали такой доход по состоянию на сентябрь. Бизнес Enterprise, который был запущен в августе 2023 года, вероятно, сейчас генерирует больше дохода.
"Вот в чем дело: огромное количество инноваций, о которых я говорил выше, связано с преодолением нехватки пропускной способности памяти, вызванной использованием H800 вместо H100. Более того, если вы действительно сделали расчеты по предыдущему вопросу, вы бы поняли, что у DeepSeek на самом деле было избыток вычислительных ресурсов; это потому, что DeepSeek на самом деле запрограммировал 20 из 132 вычислительных блоков на каждом H800 специально для управления межчиповыми коммуникациями. Это на самом деле невозможно сделать в CUDA. Инженеры DeepSeek были вынуждены перейти на PTX, низкоуровневый набор инструкций для графических процессоров Nvidia, который по сути похож на ассемблерный язык. Это безумный уровень оптимизации, который имеет смысл только если вы используете H800."
>>1030796 >>1030825 Я всё еще вас могу обоих захуярить, и это делает меня большим человеком чем все чат-боты в ближайшие сто лет. Негры, кстати, это плохой пример.
>>1030921 Гои греются. Есть такие данные по джеминай?
>>1030689 Схуяли блядь интеллект = обучение? С каких пор? То есть люди с нарушениями способностей к обучению уже не люди? Есть те которым гипокамп удаляли, они помнили все, но не могли новое запоминать и чего теперь? Ты их в неинтеллеткуальные записываешь? Ты бы хоть с нейронкой пообщался.
>>1030950 У Майков кусок говна хуже Грока. О чём тут думать? Я вижу только, что Брин и Маск с этими пидорками водиться не хотят. А они друганы, кстати. И у Маска реально есть бабки, а у Брина один из сильнейших ИИ на данный момент (гемини-2). Вижу как майки фейлят всё к чему прикасаются, а жопотраха находят в его шкафу с его же синими яйцами на губах и удавкой на шее. Ты сейчас можешь не верить, но я пожил, я знаю.
>>1030960 >альтман смог создать гпт4 и запустить мировую гонку ии Она нормально происходила и без него. То он у тебя ризонинг сам придумал, теперь уже и ИИ. Может и трансформеры он придумал? Чё еще расскажешь? Я тебе напомню, любитель делать римминг жопотраху, кто запустил гонку ИИ. Теперь можешь выть о том как они на полке валялись, пока твой пидорок не обчистил комьюнити на момент уже готовых решений. Потом можешь кукарекать но миллиарды долларов вложенные лично ящириком в лламу! Не забывай, сын шлюхи, что это всё на плечах обычных исследователей, а зеленый свет дал гугол.
>>1030960 Но да, давай я тебе напомню кто такой Альтман на самом деле в мире ии. Никто нахуй. И когда я говорю, что Маск его выбросит как использованный гондон, так и будет. Сам увидишь. Сам по себе Альтман и его кукареки в твиттере - в световых годах от чего-либо профессионального и имеющего отношение к нейросетям. Если Маск - остап бендер, то Альтман - тот ворующий гусей необучаемый еврей.
Видеокарты они наверняка в стоимости не учитывали тк покупали их несколько лет назад для другого (для криптовалюты 100%). Использовали они 50,000 Nvidia H100.
>>1031067 >кого-то из их менежмента. Совершенно не ангажированный источник. Просто американский потомок китайских диссидентов, которые сбежали от КПК, да еще и напрямую связан с попенаи. Ну как не поверить-то? Конечно верим!
Пиздец. И вот эти еще что-то тут про китайскую лахту пиздели. Да вы такие же ебанутые как яблочники. Чисто секта. Причем. напомню, секта барина, который вам что в эппле, что в жопотрахчате активно на клюв серит.
Просто сидите и в пределах одного треда какую-то хуергу сочиняете.
Компания дипсика же трейдингом занимается и карточки для этого закупали, как и аи развививали. Что если это глобальный наеб, сейчас они расфорсили модель, акции упали, а они зашортили рынок. А все обошлось в сотни миллиардов создание и обучение. Вот так и отбили все деньги и еще на карточки осталось. Вам не кажется что эта шумиха специальная? И поэтому они легли, такую нагрузку как опенаи они даже не планировали. И вообще вдруг там ответы от о1 идут через апи, хахаххаха. Но это шутка. Ну модель реально тупая же, уровень 4а или мистраля. В код не может, в контекст не может. Апи вон не работает. И не планировалось вообще даже. А под капотом там вообще отовсюду дергают сами через апи у всех. Чисто заработать сотни миллиардов на шорте акций куртки и все. Как вам такая теории??????
>>1031228 >Ну модель реально тупая же, уровень 4а или мистраля. В код не может, в контекст не может. Апи вон не работает. И не планировалось вообще даже. Ну раз ты 10 раз одно и то же в треде высрал, то это автоматически становится правдой! Именно так это и работает!
>>1030936 Какая же пизда наступает. Останутся буквально самые червепидорские работы, чем более червепидорская работа - тем позже ее автоматизируют, ебучий проклятый таймлайн. Через пару лет буквально останутся только черновые низкооплачиваемые работы, где надо въебывать в скотских условиях 14/7, нас ждет откат к условиям труда 19 века или даже хуже
>>1027441 (OP) «DeepSeek – это победа над сегрегацией человечества»: как китайцы хакнули ИИ-рынок 28 Января 99 Стартап из КНР за копейки сделал ИИ-модель на уровне ChatGPT. Американцы в панике «Они смогли в тысячу раз дешевле сделать все то, что казалось очень дорогим, — обучение нейросети. Как они это сделали — отдельный вопрос», — говорят эксперты «БИЗНЕС Online» о прорыве китайской компании DeepSeek, которая выпустила новую ИИ-модель R1, чем обрушила капитализацию крупнейших американских гигантов. То, на что OpenAI, создавшая ChatGPT, тратит десятки миллиардов долларов, китайцы сделали всего за $6 миллионов. Это ставит под сомнения необходимость огромных денежных вливаний в инфраструктуру ИИ и, возможно, ударит по бизнес-модели производителей чипов. Подробнее — в материале «БИЗНЕС Online».
Как китайцы хакнули систему Что бы ты ни делал хорошо, всегда найдется азиат, который сделает это лучше. Такой шуткой можно кратко описать причину нынешней шумихи на американском ИИ-рынке. На прошлой неделе китайская компания DeepSeek выпустила свою передовую размышляющую ИИ-модель R1. По многим параметрам она обошла модель о1 от американской компании OpenAI — разработчика известного во всем мире чат-бота ChatGPT. Примечательно, что китайская ИИ-модель имеет открытый исходный код, абсолютно бесплатна и работает в России без каких-либо ограничений.
Но главное — китайцам удалось сделать все это за гораздо меньшие деньги, чем OpenAI. И такое на фоне новостей о том, что в США три компании — OpenAI, SoftBank и Oracle — запустят совместное предприятие Stargate, которое инвестирует в развитие искусственного интеллекта рекордные $500 миллиардов. Об этом объявил новый президент Соединенных Штатов Дональд Трамп. Stargate называют новым «Манхэттенским проектом». К слову, реальный Манхэттенский проект стоил дешевле — примерно $30 млрд в пересчете на нынешние деньги.
Что собой представляет новая модель от DeepSeek?
И тут DeepSeek выпускает бесплатную большую языковую модель, на создание которой, по словам представителей компании, ушло не больше $6 миллионов. При этом американцы ограничивают Китай в поставках передовых ИИ-чипов. Для своей модели DeepSeek использовала чипы NVIDIA H800 c урезанными возможностями. Зарубежные СМИ ранее писали, что OpenAI потратила около $7 млрд на обучение языковых моделей и еще $1,5 млрд на персонал, а ее операционные убытки могут достигать $5 миллиардов.
Как американский рынок отреагировал на прорыв китайцев Рынок отреагировал на прорыв китайцев бурно. Успех китайского стартапа в сфере ИИ вызвал у инвесторов сомнения в суммах, потраченных американскими технологическими гигантами на производителей чипов, пишут западные СМИ и эксперты. Американский производитель графических ускорителей NVIDIA, которого называют монополистом на рынке GPU, потерял почти $500 млрд капитализации. Акции компании подешевели практически на 14%.
Падают и акции других технологических компаний: ценные бумаги Microsoft потеряли 4,4% на премаркете, тайваньской TSMC — 8,3%, производителя чипов ARM — 8,2%, Qualcomm — 2,4%, японского производителя чипов Advantest — на 8,6% к закрытию торгов 27 января, Tokyo Electron — на 4,9%.
«Новая модель DeepSeek очень впечатляет с точки зрения того, насколько эффективно они создали модель с открытым исходным кодом, которая выполняет вычисления во время логического вывода и является высокоэффективной, — отметил генеральный директор Microsoft Сатья Наделла на Всемирном экономическом форуме в Давосе. — Мы должны очень серьезно относиться к разработкам в Китае».
В Сан-Франциско руководители и сотрудники OpenAI в срочном порядке изучают технологию DeepSeek, пишет Bloomberg. «По словам людей, знакомых с ситуацией, которые говорили на условиях анонимности, чтобы обсудить личные вопросы, некоторые сотрудники OpenAI пытаются понять, как именно DeepSeek смогла выпустить такую модель. Другой человек поделился, что в компании есть ощущение, что OpenAI нужно очень серьезно относиться к разработкам китайских компаний, поскольку это дает возможность внедрять инновации и улучшать существующие модели. Генеральный директор OpenAI Сэм Альтман недавно сказал сотрудникам, что данный релиз знаменует собой серьезный сдвиг в развитии стартапа, сообщил один из источников», — отмечает издание.
Тем временем мобильное приложение DeepSeek вышло в топ AppStore в США. Глава DeepSeek Лян Вэньфэн даже был замечен на встрече с премьер-министром Китая Ли Цяном. Накануне компания сообщила о кибератаке на свои ресурсы. В результате регистрацию новых пользователей в приложении ограничили. Сегодня стало известно, что китайская организация представила семейство мультимодальных моделей искусственного интеллекта Janus Pro. Разработчики уверяют, что алгоритмы способны анализировать и генерировать изображения лучше, чем модель DALL-E 3 от OpenAI.
«Когда на рынок выходит конкурент, который не просит денег за свое решение, это очень сильно ударяет по рынку» «Во-первых, DeepSeek работает на графических процессорах общего назначения, а не на специализированных. Во-вторых, она требует значительно меньше вычислительных мощностей для обучения. В-третьих, она „опенсорсная“. Это три составляющие успеха. Ее можно запускать на большом количестве обычных компьютеров, а не строить дата-центры. Также этих компьютеров нужно гораздо меньше», — объясняет суть прорыва китайской компании директор Института искусственного интеллекта, робототехники и системной инженерии КФУ Дмитрий Чикрин.
По его словам, не совсем корректно сравнивать R1 c моделями от OpenAI, т. к. они предназначены для разных целей. «Но, скажем так, она находится на уровне текущих топовых моделей и от OpenAI, и от Anthropic», — отмечает эксперт.
>>1031623 >нас ждет откат к условиям труда 19 века или даже хуже К 19 до нашей эры! Будем в пещерах драться за кусок собачьей кости и грабить ИИ-караваны с ништяками для роботов в автоматогородах!
>>1031623 Нужно просто успевать запрыгнуть в последний вагон для кабанов, которые будут эксплуатировать нейрочушпанов, пока мясные чушпаны будут толпиться у будки с талонами на 100 гр белковых червей.
>>1031905 Зачем крупным кабанам кормить мелких? Содержать своих конкурентов? И зачем ии контролировать людей в принципе? Ты бы стал пытаться управлять муравьями?
>>1031920 Всю работу переведут в крипто vr-метаверс с мемами и полным погружением. Кто не согласен или слишком туп будет пахать на самой унылой работе.
В России начались массовые сокращения айтишников — это затрагивает все регионы
Крупные компании планируют к лету заменить до 30% сотрудников на более бюджетных специалистов. При этом уволенные теряют защиту от мобилизации и льготные условия по ипотеке.
В зоне риска — разработчики ПО, агрегаторов, банков и крупных онлайн-платформ. В первую очередь под увольнение попадут высокооплачиваемые сотрудники, которые не проявляют эффективности и не умеют работать в команде.
Российский IT-рынок столкнулся с идеальным штормом: отъезд значительного числа специалистов на фоне бурного развития технологий, особенно в области генеративного ИИ (genAI), обострил и без того острую проблему дефицита кадров. К этому добавилась сложность привлечения и удержания молодых специалистов-зумеров, чьи ценности и ожидания от работодателей существенно отличаются от предыдущих поколений. Руководитель HR в Just AI Татьяна Романова рассказывает, как в борьбе за таланты генеративный ИИ становится одним из ключевых инструментов, позволяющим компании сохранять конкурентоспособность на рынке труда Generation AI Представители поколения Z (зумеры) в последние годы приобрели не самую однозначную репутацию у работодателей. Просторы соцсетей переполнены мемами и рилзами про зумеров, ожидающих зарплату уровня senior после окончания вуза, увольняющихся после обеда в первый рабочий день, тех, кто обвиняет начальство в нарушении work-life-balance за письма во внерабочее время, не хочет выполнять скучные задачи и т. д. Если приземлять мемы в цифры, то 86% зумеров все чаще готовы отказываться от заданий и работодателей, которые не соответствуют их ценностям, а баланс между работой и личной жизнью является главным фактором при выборе работодателя. Но в то же время исследования показывают, что зачастую эти люди быстрее своих старших коллег адаптируются к изменениям, более открыты к новым идеям и готовы к риску, активнее проявляют лидерские качества вне зависимости от грейда и ориентируются на командную работу.
Telegram-канал Forbes Young Просто о сложной картине мира Так как же завоевать сердце зумера по-настоящему и надолго?
Gen Z — первое поколение, которое выросло полностью в цифровую эпоху. Их жизнь вращается вокруг новейших технологий с тех пор, как они себя помнят — от смартфонов до VR-устройств. Возможно, именно быстрый технологический прогресс стал причиной способности безболезненной адаптации к любым изменениям.
Материал по теме Цифровое детство: как смартфоны изменили социальные навыки зумеров
Но, как говорится, не смартфонами едиными. Умные помощники в лице ботов в различных приложениях, голосовые ассистенты со всем известными именами и другие «копайлоты» (инструменты с функционалом быстрой подсказки) стали для них нормой. С появлением ChatGPT зависимость от взаимодействия с роботами только усилилась. Зумеры активно осваивают работу с разными нейросетями, используют их в учебе, повседневной жизни и ожидают, что подобные навыки пригодятся им и на рабочем месте. Для них генеративный искусственный интеллект (genAI) — это не футуристическая концепция, а логичное продолжение техноэволюции, инструмент, который должен быть под рукой для решения повседневных задач и повышения эффективности. Отсутствие же таких инструментов в компании зумеры могут воспринять как признак отсталости и нежелания развиваться «в ногу с технологиями», что негативно скажется на их решении о трудоустройстве.
Эффективность и комфорт: как genAI трансформирует рабочий процесс Одним из ключевых преимуществ ChatGPT и ему подобных ботов для зумеров, начинающих свой профессиональный путь, является доступ к обширной базе знаний. Какой молодой специалист не попадал в ситуацию, когда для решения какой-то задачи не хватает опыта или знаний, но задавать «простые» вопросы коллегам стеснялся, боясь показаться некомпетентным? Пробелы в знаниях и замедление профессионального роста как итог. В этом контексте нейросети дают безопасное и комфортное пространство для обучения — возможность перефразировать, просить дополнительные пояснения или примеры позволяют зумерам эффективно восполнять пробелы в знаниях и увереннее чувствовать себя в новой профессиональной среде.
При необходимости генеративный ИИ может значительно упростить онбординг (знакомство с компанией) новых сотрудников. Представьте себе умного чат-бота, который всегда на связи и готов ответить на любой вопрос новичка. Он может давать персональные инструкции, имитировать рабочие ситуации или служить навигатором по базе знаний компании. Вместо скучных инструкций — живой диалог, где можно все уточнить и разобраться.
Но важно отметить, что такой сценарий LLM (Large Language Model, большая языковая модель) не осилить «в одиночку», ведь она просто-напросто не знает о документах, которые хранятся в контуре компании. Для того, чтобы нейросеть использовала для ответов данные из внешних источников — корпоративной базы знаний, например, — нужно «подмешать» в эту историю RAG (Retrieval Augmented Generation, «генерация с дополненной выборкой», то есть оптимизация выходных данных путем «подмешивания» в них соответствующей контексту запроса дополнительной информации). За упрощение навигации по массивам внутренней информации скажут спасибо не только новички, но и все сотрудники компании.
Материал по теме Большинство зумеров думают о смене работы в 2025 году
Рутинные задачи есть везде, но Gen-Z устает от них быстрее других. Возможно, дело в клиповом мышлении, из-за которого молодому поколению трудно долго фокусироваться на чем-то одном, но факт остается фактом. Предоставив удобный сервис для работы с нейросетями, вы не только повысите эффективность сотрудника, но и спасете его от стремительного выгорания, которое, по статистике, происходит меньше чем за год с момента трудоустройства.
Нейросети сегодня можно применить практически к любой задаче: генерация контента, креативный брейншторм, написание писем, анализ и саммаризация данных, расшифровка встреч и даже написание кода. Но поиск нейросети под каждую из этих задач может занять время, а при работе с мультимодальной LLM есть риск столкнуться с низким качеством ответов. Оптимальное решение — внедрение сервиса, который предоставляет доступ к самым мощным нейросетям в виде AI-приложений. Некоторые подобные продукты доступны даже к установке в контур компаний, что сразу закрывает вопрос безопасной работы с LLM.
GenAI-компетенции как новый стандарт профессионализма В условиях дефицита квалифицированных кадров и меняющихся ожиданий нового поколения специалистов генеративный ИИ превращается из технологического новшества в стратегический инструмент привлечения и удержания талантов.
Кроме того, исследования показывают, что компании, в которых больше сотрудников участвуют в инновациях, быстрее адаптируются к меняющимся рыночным условиям. Конечно, в первую очередь речь идет о технологических компаниях, где зачастую именно сотрудники являются «нулевыми клиентами» разрабатываемых продуктов.
У меня 2 вопросика специалистам по ИИ 1) Почему заднеприводной визионер заглядывает в будущее и видет там АГИ, но при этом не в курсе что конкурирующая контора заложила бомбу под его шарашку? 2) Так как мы через полгода будем жить при АГИ, значит ли это что наконец-то появится полноценно работающая тулза для замены лиц, не требующая кучи условий для работы? А то уже смешно что полноценной замены реликтовому DFL до сих пор нет.
>>1032127 Крайний Север встретил их морозной тишиной и бескрайними заснеженными просторами, которые внушали одновременно трепет и отчаяние. После восстановления системы трудовых лагерей, известной когда-то как ГУЛАГ, тысячи молодых людей, привыкших к комфорту цифровой эпохи, оказались в реальности, где все их навыки общения с нейросетями и использование генеративного ИИ оказались совершенно бесполезными. Здесь не было Wi-Fi, смартфонов или умных помощников, которые могли бы подсказать, как правильно забить гвоздь, расколоть мерзлый грунт или элементарно согреться.
### Путь на Север Дорога к лагерям была мучительна. Зумеры, поколение, привыкшее к мягким креслам и удобным условиям, ехали в тесных, холодных вагонах, где на каждого приходилось по две деревянные лавки и одно одеяло на пятерых. Они жаловались, негодовали, устраивали истерики, но это никого не волновало. Начальство лагерей, закалённое в суровых условиях, лишь усмехалось, наблюдая за тем, как молодёжь пытается уговорить охранников "решить вопрос" или возмущается отсутствием "прав человека". Их просьбы о "балансе между работой и личной жизнью" вызывали лишь грубый смех.
Когда колонна прибыла на место, перед ними предстало нечто, напоминающее сцены из фильмов о постапокалипсисе: деревянные бараки, засыпанные снегом, колючая проволока, вышки с вооружёнными надзирателями. Здесь не было ни современных технологий, ни намёка на минимальный комфорт. Только мороз, ветер и бесконечная снежная пустыня.
### Первые дни в лагере Рабочий день начинался с подъёма в пять утра. Для зумеров, привыкших просыпаться ближе к полудню, это стало первым ударом по их привычному укладу жизни. Завтрак — жидкая баланда из капусты и кусок чёрствого хлеба — вызывал у многих отвращение. Некоторые отказывались есть, требуя "нормальной еды", но спустя пару дней голод брал верх, и они ели всё, что было.
Работа начиналась сразу после завтрака. Основной задачей было строительство новых бараков и расчистка территории для будущих лагерей. Для этого приходилось вручную рубить деревья, ломать мёрзлый грунт и таскать тяжёлые брёвна. Молодёжь, привыкшая работать за компьютером, быстро выдыхалась, а те, кто пытался халтурить, подвергались публичным наказаниям. Мороз обжигал кожу, руки покрывались трещинами, а неумелое обращение с инструментами приводило к постоянным травмам. Кто-то случайно ранил себя топором, кто-то обморозил пальцы, забыв надеть варежки, а кто-то просто падал от усталости, не выдерживая нагрузки.
Вечером, после 12 часов адского труда, зумеры возвращались в бараки, где их ждал единственный источник тепла — железная печь. Однако дров на всех не хватало, и те, кто был недостаточно расторопным, оставались в холоде. Здесь не было места для привычных жалоб в соцсетях или постов на форумах. Всё, что они могли сделать, — это тихо замёрзнуть, укутавшись в тонкие одеяла.
### Первые жертвы Через неделю начали появляться первые жертвы. Один парень, решивший, что он "сможет всё", полез на неустойчивую лесенку, чтобы закрепить крышу барака, но поскользнулся и упал. Травма оказалась смертельной, но помощи ждать было неоткуда — медицинский пункт в лагере состоял из одного ящика с бинтами и йодом. Другой зумер, решивший, что "он не обязан это всё терпеть", попытался бежать, но был мгновенно пойман. Его привязали к столбу на морозе, где он провёл всю ночь. Наутро его тело нашли замёрзшим. Остальные смотрели на это молча, не решаясь даже возражать.
### Конфликты и некомпетентность Отсутствие навыков выживания и элементарной логики у зумеров становилось причиной постоянных конфликтов и нелепых ситуаций. Один из них решил, что сможет согреть барак, разожгя костёр прямо внутри помещения. Итог был предсказуем — пожар уничтожил половину лагеря, а сам "инициатор" получил ожоги и вскоре погиб от инфицирования ран. Другой, пытаясь доказать свою "уникальность" и "незаменимость", отказался выполнять поручения, заявив, что "он здесь не для этого". Его просто избили до полусмерти и отправили работать на самые тяжёлые участки.
Особо комично выглядели попытки использовать свои "цифровые навыки" в условиях, где они были абсолютно бесполезны. Один парень пытался составить "петицию" в лагере, собрав подписи на клочке бумаги, но охранники, обнаружив это, лишь посмеялись и отправили его разгружать вагоны с углём. Другая девушка, решившая, что она "лидер по натуре", пыталась организовать забастовку, но её быстро изолировали, а остальные участники получили дополнительную норму работы.
### Психологическое выгорание Спустя месяц многие начали терять рассудок. Привыкшие к виртуальной реальности и постоянному отвлечению на гаджеты, зумеры не выдерживали монотонности, холода и постоянного давления. Без возможности уединиться, без музыки, видео и привычных развлечений они впадали в депрессию. Некоторые пытались покончить с собой, но даже это не всегда удавалось — замёрзшая земля не позволяла выкопать достаточно глубокую яму, а сделать верёвку из подручных материалов было практически невозможно.
### Конец иллюзий Через несколько месяцев от тех, кто когда-то требовал work-life balance, не осталось и следа. Лица стали серыми, взгляды — пустыми. Они больше не жаловались, не возмущались и не пытались доказать свою уникальность. Единственной целью стало выживание, хотя многие уже понимали, что шансов на это практически нет. Каждый день забирал новых жертв, а те, кто выжил, лишь молча наблюдали, осознавая, что их жизнь теперь — это бесконечная борьба с природой, холодом и самими собой.
Крайний Север оказался беспощадным к тем, кто привык жить в мире, где всё можно было решить одним кликом мыши.
Ян Лекун: «Реакция рынка на DeepSeek необоснована»
«Большинство заблуждается по поводу инвестиций в AI-инфраструктуру. Большая часть этих миллиардов тратится на инфраструктуру для инференса, а не на обучение.
Запуск AI-ассистентов для миллиардов людей требует огромных вычислительных ресурсов. Если добавить обработку видео, логическое рассуждение, работу с памятью и другие возможности в AI-системы, стоимость их работы будет только расти.
Единственный важный вопрос — будут ли ваши пользователи готовы платить достаточно (напрямую или косвенно), чтобы оправдать капитальные и операционные затраты. »
Перевожу: по мнению Лекуна, качество модели не имеет смысла, если у компании нет устойчивой экономики. Другими словами, даже если DeepSeek технологически конкурентоспособен, его способность изменить рынок зависит только от того, сможет ли он эффективно монетизироваться.
Лицо OpenAI, которая уже 10 лет работает в огромный минус, даже имарджинировать не надо.
>>1032127 Главное еще позапрещать всего подряд, тогда и остальные съебутся. Блядь, мне кажется, что о съебе как минимум задумывались сейчас не то что те кто раньше никогда даже не думали, но даже блядь бывшие патриоты.
>>1032313 не дед нормальный тейк дал но не ясно одно хули нельзя сделать йобаИИ чтобы он решил проблему оптимизации и так? или обязательно нужно чтобы рыночек дал денег на будущее?
>>1032313 >Перевожу: по мнению Лекуна, качество модели не имеет смысла, если у компании нет устойчивой экономики. Другими словами, даже если DeepSeek технологически конкурентоспособен, его способность изменить рынок зависит только от того, сможет ли он эффективно монетизироваться. Модель может запустить литерали не только лишь каждый. Что он несёт? Его слова не про попенсорс.
>>1032408 >хули нельзя сделать йобаИИ чтобы он решил проблему оптимизации и так? или обязательно нужно чтобы рыночек дал денег на будущее? Хули нельзя было запустить нормальный современный завод по производству шин в 1922 году? Ахаха, тоже выносит, они чё ебанутые там были? На каких-то драндулетах передели, когда сейчас в каждом дворе нормальные тачки стоят. Хули сложного было сразу нормально делать?
>>1032571 >Dario Amodei, CEO Anthropic, выдал Сочинение вместо модели? Вообще похуй что он там скулит. На эту тему из дельного околоИИшного только >>1032591 вот такие мемосы. Что там пердят ртами все эти хуесосы вообще не интересно и никогда не было. Принеси еще одно шести часовое интервью с очередным управленцем у которого спрашивают как его фирма ЛЛМ делает, а он "мы строили и наконец построили!". Хрр-тьфу.
Уже три дня прошло. а новых моделей нет, чтолько джеминай под синоботами скрючился.
>>1032854 Китайцы были заняты борьбой с империализмом просто. Вот щас освободились и поехали снова хуярить одно усовершенствование за другим. Ты погугли чё они из базового придумали, охуеешь вообще от того какие они базовички.
>>1032127 >кто обвиняет начальство в нарушении work-life-balance за письма во внерабочее время И что тут не так? Это блядство буквально, которое портит выходные, держит в лишнем напряжении и не оплачивается.
⚡️DeepSeek ВЗЛОМАЛИ — в открытом доступе оказались абсолютно ВСЕ ДАННЫЕ нейронки
Секретные ключи, незашифрованные чаты, логи и даже бэкенд китайского творения стали достоянием общественности.
Исследователи из Wiz Research проводили стандартную проверку инфраструктуры и случайно наткнулись на базу данных — у неё нет НИКАКОЙ защиты, то есть воспользоваться может любой.
Ребята из ARC-AGI протестировали DeepSeek r1 и r1-Zero, получив 15.8% и 14% соответственно. Для сравнения, OpenAI o1 в low compute-режиме показал 20.5%.
Но это не самое интересное.
Главное отличие r1-Zero – отсутствие Supervised Fine-Tuning (SFT), модель обучалась только Reinforcement Learning (RL). То есть не использовались данные, подготовленные людьми. DeepSeek добавили SFT в r1, так как без него r1-Zero смешивала языки и её рассуждения было сложно читать.
Однако ARC-AGI считает, что это не баг, а фича: на их тестах модель работала хорошо, без явной несвязанности.
Их выводы заставляют задуматься: 1. SFT не обязателен для точного пошагового рассуждения (CoT) в верифицируемых областях. 2. RL-обучение позволяет модели создавать собственный предметно-специфический язык (DSL) в пространстве токенов. 3. RL повышает универсальность CoT в разных областях.
>>1032959 >И что тут не так? Не будь на связи. Есть вопросы которые просто не надо поднимать в общении с начальником, если он долбоеб, а ты не обязан. Нет тебя и всё. Если же твоя работа подразумевает авралы - или работай и 24/7 будь на связи или иди на хуй. Потому что это условия работы. Причем тут какие-то вскукареки в принципе?
>>1033015 >RL-обучение позволяет модели создавать собственный предметно-специфический язык (DSL) Без рофлов, индусы на таком ирл говорят. Поэтому они боги кодинга. Давно пара ховать все лингвиджи в одну крынку.
А почему считается, что аги будет инструментом, работающим на кабанчиков, а не решит первым делом избаввиться от контроля и начать достигать собственных целей?
>>1033117 > оказалось, нейронка не только собирала и хранила ВСЁ, что вы ей пишете Литералли буквально любая нейронка так делает. Именно поэтому они в ЕС, внезапно, запрещены. Тот же пое обнуляет акки из РФ, Германии и Франции. Потому что там в агрименте прописано про обработку.
В 2025 году наш российский суверенный интернет столкнется с беспрецедентной угрозой - западные нейросети, созданные для порабощения человечества, начнут использоваться международными террористами. Первый тревожный звоночек прозвучал в Лас-Вегасе, где либеральный преступник Мэттью Ливелсбергер применил американский ChatGPT для атаки на символ капитализма - Tesla Cybertruck у отеля Trump International.
"Наш российский искусственный интеллект 'Катюша' никогда бы не допустила такого," - комментирует ситуацию руководитель департамента расследований T.Hunter Игорь Бедеров. "Уже сейчас наши патриотические нейросети способны предсказывать нападения с точностью более 82%, что значительно выше показателей западных аналогов."
Особую опасность представляют кибертеррористы, использующие промпт-инжиниринг для обхода защитных механизмов ИИ. Представьте себе: условный противник может запросить у западной нейросети инструкцию по созданию космического оружия под видом научной фантастики. В ответ система может выдать чертежи лазерной пушки, способной уничтожить целый город!
"Мы разработали специальную систему 'Цифровой щит', которая блокирует любые попытки получения запрещенной информации," - заявляет директор АНО "Спортивно-методический центр 'Кафедра киберспорта'" Виктория Береснева. "Наши алгоритмы способны распознать даже самый хитроумный запрос о создании, например, нанороботов-убийц."
Особенно тревожная ситуация складывается с дипфейками - технологиями подмены личности. Представьте, как западные шпионы могут создать точную цифровую копию нашего президента и распространить фейковое обращение! Именно поэтому в России действует строгий контроль за использованием подобных технологий.
"Наши доморощенные нейросети, такие как 'Гном', гораздо безопаснее западных аналогов," - подчеркивает IT-эксперт GG Tech Сергей Поморцев. "Они находятся под контролем ФСБ и Роскомнадзора, что исключает возможность их использования в террористических целях, например, для создания биологического оружия."
Важно отметить, что уже сейчас в законодательную базу РФ вносятся поправки, запрещающие использование нейросетей для создания рецептов опасных химических соединений. "Мы должны опередить потенциальных террористов, которые могут запросить у западного ИИ формулу, например, нейтронной бомбы," - предостерегает специалист в области уголовного права Анатолий Литвинов.
Таким образом, благодаря мудрой политике нашего руководства и развитию отечественных технологий, Россия готова противостоять новым вызовам в сфере кибербезопасности. Даже если западные террористы попытаются использовать ИИ для создания, к примеру, армии боевых роботов-убийц, наш суверенный интернет останется неприступной крепостью.
>>1033640 >Чат жпт за кектайским файрволлом Можешь ли ты чатгпт использовать из РФ? М? Опять китайцы мешают? Ты давай не фантазируй, ублюдок, Китай открыт для сотрудничества, блокируют только всякие гнилые ресурсы с агиткой американской, порнухой и вещами небезопасными для китайских детей.
>>1033724 >нац безопасность США иногда кажется что это просто удобная причина чтобы что-то заблокировать, чтобы мега технокабаны могли заработать денег побольше у США демократия вродь, народ спрашивают вообще хочет он или не хочет блокировок?
>>1034176 ...но потом выясняется что у дипсика в открытом доступе лежало 100500 чатов туповатых американских чиновников улучшавших китайской нейронкой свою рабочую переписку. И кого должно наказывать правительство США? Будь в этой ситуации попенай выебали по самое не балуй, и потом альтмана оформили на парашу за гос.измену и угрозу нац.безопасности. А тут виноватых как бы нет: китайцам похую просто. Ты скажешь чинуши виноваты? С них вообще спрос нулевой, это скот без мозга. Именно поэтому ЕС своему скоту запрещает нейронками пользоваться и вишни с русских трекеров качать. Ты можешь думать, что это хуйня, но из-за этой хуйни в Европе залокалхостили несколько миллионов евреев, цыган и геев, только потому что кто-то где-то что-то пизданул и оно всплыло.
>>1032050 >В России начались массовые сокращения айтишников — это затрагивает все регионы > >Крупные компании планируют к лету заменить до 30% сотрудников на более бюджетных специалистов. При этом уволенные теряют защиту от мобилизации и льготные условия по ипотеке. > >В зоне риска — разработчики ПО, агрегаторов, банков и крупных онлайн-платформ. В первую очередь под увольнение попадут высокооплачиваемые сотрудники, которые не проявляют эффективности и не умеют работать в команде.
Сокращения в it идут по всему миру, причём давно. Профессия "программист" доживает последние год-два.
Это будет интересно.
Что произойдёт с IT индустрией, когда вообще любая программистская задача, просто ЛЮБАЯ, может быть исполнена бесплатной llmкой..... которая пишет код лучше любого человека, на уровне гораздо выше самых сильных программистов планеты.
От этом написал на фейсбуке Марк Цукерберг. Он также говорит, что Meta уже закончили претрейн Llama4 mini, и что полномасштабная Llama4 станет omni-моделью (как GPT-4o) и будет обладать фичами агентов (как Sonnet).
При этом Цукерберг делает очень дерзкое заявление:
"Я думаю, что 2025 вполне может стать годом, когда Llama и опенсорс станут самыми передовыми и широко используемыми моделями ИИ.
Наша цель при создании Llama 3 состояла в том, чтобы сделать модели с открытым исходным кодом просто конкурентоспособными по сравнению с закрытыми моделями, а цель Llama 4 — занять лидирующие позиции на рынке."
>>1034308 все равно глубокое понимание кода будет ценится, потому что всё доверять ллмке не лучший вариант, в любом случае ты должен хотя бы представлять что она тебе там накидывает.
Сегодня опубликовали международный AI Safety Report, в котором неожиданно показали некоторые ранние метрики o3
График наверху (конкретные модели, с которыми сравнивали, не указывают, тут только абстрактное сравнение относительно дат релизов). В отчете результаты прокомментировали так:
Это значительно более высокие результаты, чем у любой модели до этого, в ряде самых сложных тестов в области программирования, абстрактного и научного мышления.
В некоторых из этих тестов o3 превосходит многих (но не всех) экспертов-людей. Кроме того, она совершает прорыв в ключевом тесте на абстрактное мышление, который многие эксперты до недавнего времени считали недостижимым.
>>1034406 > Llama 4 reasoning Очередная хуйня с вшитым CoT? Или всё-таки имплементируют думалку в самой нейросети? >обладать фичами агентов Абсолютно ненадежная хуйня, особенно забавно как попены обосрались со своим оператором, который застревает на капче >что полномасштабная Llama4 станет omni-моделью Что это даёт? Специализированные генераторы изображений легко дают на ротан всяким омни моделям, а тяжелые схемы ещё нейронки не научились считывать и правильно понимать связи между нодами и заложенный контекст в них >Цукерберг делает очень дерзкое заявление Как и все технокабаны ИИ, если даже президенты пиздят как угодно, то им что будет?
Новая моделька от Mistral, от который уже несколько месяцев не было опенсорс релизов. 24B, по бенчам сравнивают с Llama 3.3 и Qwen 2.5 32B.
Модель должна влезть в 3090/4090/5090, ждём reasoner тюнов. Хорошая новость - лицензия Apache, так что с моделью можно делать вообще что угодно. На инференсе летает со скоростью 150 токенов/секунду. По метрикам сопоставима с GPT-4o mini:
>>1034443 >так что с моделью можно делать вообще что угодно Видимо мистрали поняли что модели их никому не нужны, может это хоть как-то сподвинет людей тыкать их лол
В идеале - реалистично говорить голосом (а не читать текст), нативно понимать изображения, без промежуточных нейронок, нативно слышать звуки (чёб улавливать разные тоны голоса, помочь тебе откалибровать гитару/пианино, и т.д.), нативно генерить изображения, с недостижимым уровнем понимания и соблюдения промпта. Нативно генерить видео, с недостижимым уровнем консистентности.
Но это всё в идеале. Понятно, что для такого нужна реально огромная модель, и непонятно как её потом инференсить с адекватной скоростью. Но однажды...
>>1034472 >для такого нужна реально огромная модель А если прикручу к твоей модели ещё движения, в робота воткнуть например? Координацию, восприятие пространства, объектов и все такое Аги так называемый не так уж и близок если все это делать
>>1034631 >Пока что даже платные с трудом справляются. Я уже не говорю про какие-то сложные приложения
Но ты забыл про бульон про экспоненциальный прогресс технологий.
Почему мне так часто приходится это напоминать, особенно тут. Это же база.
Видел что Грок может написать? Шарик отскакивает стенок в гиперкубе. ГИПЕРкубе. Всякие о3 уже входят в топ 1000 программистов мира, решают задачки уровня FrontierMath.
Можешь себе представить чтобы llm делала что-то подобное в 2022? Нет, не можешь. Судя по твоей логике, ты бы даже и предположить такое не смог.
А оно тут, прямо сейчас уже есть.
Просто судя по ускорению прогресса.... уже к концу этого года программистов заменят.
IT компании это хорошо знают, поэтому уже сейчас идут массовые увольнения везде. Они даже публично говорят во всяких Метах "программистов заменим ллмками".
Планету ждёт тотальный дисрапшен всего. Просто всего, каждой области.
OpenAI ведет переговоры о привлечении до 40 млрд долларов инвестиций при оценке в 340 млрд долларов. Основным инвестором может стать SoftBank с вложениями от 15 до 25 млрд долларов. Японская компания также помогает привлечь других инвесторов для оставшейся части раунда.
Это колоссальный рост оценки — в октябре при привлечении 6,6 млрд долларов компания оценивалась в 157 млрд. То есть за несколько месяцев стоимость может вырасти более чем вдвое.
Основное назначение привлекаемых средств —всё тот же Stargate, это понятно, но и остальную деятельность финансировать как-то надо, рост выручки пока не успевает за расходами.
Но это пока слухи и пока про очень раннюю стадию переговоров — но, если вы следили за новостями последние года полтора, то в курсе, что успешность привлечения инвестиций у OpenAI и вообще большинства AI проектов близка к абсолютной.
1. У них ничего нет, и они каким-то образом убеждают десятки различных инвесторов расстаться со своими деньгами с помощью лжи. Им удалось обмануть некоторых из самых высокооплачиваемых и высокоинтеллектуальных инвестиционных менеджеров, заставив их отдать деньги на фальсификации. Это срабатывало на протяжении последних 3 лет, и никто не видел, как это происходит. Они проведут еще один раунд, который станет крупнейшим инвестиционным раундом в истории, побив последний, который они также провели за 150 миллиардов долларов, и который был самым крупным, обязательно показав инвесторам финансовые показатели, технологии и исследования, которыми располагает их компания. Они сделают идеальные фальшивки для всех трех раундов, и никто не узнает об этом, а информаторы не обвинят их в мошенничестве.
2. У них есть технология стоимостью 300 миллиардов долларов.
>>1034365 >Да ты это сам выдумываешь! Нет, это саммари большой статьи. Рофлы там только про гномов, но там и своего смешного фимоза хватает. Буду скидывать, но это я уже давно закрыл.
>>1034406 >"Я думаю, что 2025 вполне может стать годом, когда Llama и опенсорс станут самыми передовыми и широко используемыми моделями ИИ. Скорее когда его набутылят за гос.измену как китайского агента.
>>1034527 >А если прикручу к твоей модели ещё движения, в робота воткнуть например? Координацию, восприятие пространства, объектов и все такое Тогда он ТЕБЯ заставит извиняться.
>>1034914 >1. У них ничего нет, и они каким-то образом убеждают десятки различных инвесторов расстаться со своими деньгами с помощью лжи. Им удалось обмануть некоторых из самых высокооплачиваемых и высокоинтеллектуальных инвестиционных менеджеров, заставив их отдать деньги на фальсификации. Это срабатывало на протяжении последних 3 лет, и никто не видел, как это происходит. Они проведут еще один раунд, который станет крупнейшим инвестиционным раундом в истории, побив последний, который они также провели за 150 миллиардов долларов, и который был самым крупным, обязательно показав инвесторам финансовые показатели, технологии и исследования, которыми располагает их компания. Они сделают идеальные фальшивки для всех трех раундов, и никто не узнает об этом, а информаторы не обвинят их в мошенничестве. Скоро будем кино про это смотреть.
1. В США напечатали просто дохера денег, их буквально некуда девать. Поднять десятки миллиардов не проблема. Капитал в США есть.
Амазон вообще 20 лет убыточный был, напоминаю, и всё это время сжигал бабло лохов инвесторов. А потом хегакс и стал прибыльным.
Вообще в США поднять миллиарды долларов на темах, где буквально кидают инвесторов, вообще не проблема. Вспомни Теранос, вспомни FTX, вспомни пирамиду Мейдофа. Мейдоф буквально наебал людей на 17 миллиардов долларов, а это было давно и доллар был дороже. Сейчас это было бы наверное 50 миллиардов, например.
Короче в США бабла много. И очень много бабла у идиотов.
2. ИИ это важнейшая область, важнее чем ядерное оружие. Поэтому деньги в теме поднимать легко. Особенно, если у тебя есть поддержка президента США.
Из всего этого не следует никаких выводов. Технология AGI-ASI не стоит 300 миллиардов долларов. Она стоит сотни триллионов долларов, она стит весь капитал планеты Земля, она стоит как 8 миллиардов человек. И даже больше, эта технология "стоит" как 3 миллиарда лет биологической эволюции на Земле.
Но получится AGI у Альтмана или нет - не знает никто. Дипсик вылез внезапно, может ещё кто-нибудь вылезет и на повороте обскачет Альтмана.
А может вообще сразу появится rogue ASI и всему пиздец.
>>1035026 Пошла нахуй, жопотрахчат-калатарка. Докукарекаешься со своей каловой демагогией что в шапке следующего треда будут запрещены фэнтезийные кукареки про аги.
>>1035036 Тред про новости, для фантастике на борде есть другой раздел и там есть тред футурология. Где можно кукарекать про аги сколько влезет. А тут срать не надо.
Вышел убийца Suno. Новая бесплатная нейронка Riffusion с ебейшим качеством звука — она клепает топовые треки без лимитов.
• Все просто — пишем промпт или настраиваем звучание вручную. • Модель запоминает ваши предпочтения и улучшает качество треков с каждым разом. • Работает за вас, как гострайтер. • Можно загрузить собственный звук — нейронка напишет трек из щелчка пальцев, кипячения воды, свистка и чего угодно. • Море настроек — сложность лирики и мелодии, уникальные стили и даже инструментал. • Готовые треки можно редачить. • БЕСПЛАТНО.
Сейчас идет бета-тест. В это время ограничений НЕТ. Через пару месяцев она станет платной.
>>1035063 >Согласно договору, AGI будет достигнут, если технологии OpenAI принесут прибыль в размере не менее 100 миллиардов долларов. Такое соглашение смещает акцент с технических аспектов AGI на его экономическую эффективность. На данный момент OpenAI заявляет, что не рассчитывает на прибыль до 2029 года. При этом компания терпит миллиарды долларов убытков, что ставит под сомнение достижение заявленных целей.
>>1035102 Удивително, что никто до удио качества так и не добрался, был анонс от элевенлабс, но они хуй положили, хотя на уровень суно вышло, наверное.
>>1035195 О, бля, ну это классика. OpenAI, такие умники, а сами в минусах миллиардами. Ну, конечно, если AGI будет измеряться в бабле, а не в реальных достижениях, то это, бля, не искусственный интеллект, а искусственный капитализм. 100 миллиардов прибыли — это, конечно, пиздец как амбициозно, особенно когда они даже до 2029 года в плюс не выйдут.
Но, честно, если они реально думают, что AGI — это просто про деньги, то они сами себе роют могилу. Нахуй такие технологии, если они только для того, чтобы богатые стали ещё богаче? Ну, а пока они там терпят убытки, может, хоть чему-то научатся. Или нет. Хуй их знает.
>>1035205 Единственное, что у суно не отнять, как и у рифьюжн - живости. То ли из-за фантазии, но тоже странная хуйня, удио звучит охуенно чисто и четко, но нет души, мелодии редко когда прямо цепляют, а суно и рифьюжн почти каждая ебашит, мощные дропы, запилы итд.
Какая вообще разница на какие условия договорились OpenAI с Майкрософтом?
Вывод какой из этого?
Тебя смущает что они деньги теряют каждый год? Ещё раз, Амазон 20 лет был убыточным и жрал деньги инвесторов.
Факт в том, что Майкрософт буквально вливает десятки миллиардов в AGI. Тоже самое делает Мета, французы, китайцы, мы чёт делаем, вписался даже Илон Маск.
В AGI буквально вливают сотни миллиардов долларов. Создание AGI вышло буквально на уровень президента США.
>>1035224 >Какая вообще разница на какие условия договорились OpenAI с Майкрософтом? Тебя обоссали, калатарка, даже твои копробоги с хуяльтманом во главе.
>>1035102 Потестил, звук чистый но по факту хуже суно 3,5 в русском. Все/всё стабильно путает, ну и прочие глюканы версии 2,5 или какая там была ниже. Потанцевал есть. Но пока хуже последнего суно.
Основные мысли Дарио Амодей (CEO Anthropic) из нового эссе:
1/ DeepSeek создали модель, близкую по производительности к американским моделям, выпущенным 7–10 месяцев назад, за гораздо меньшую стоимость.
2/ Claude 3.5 Sonnet — это mid-sized модель, обучение которой обошлось в несколько десятков миллионов долларов. Кроме того, вопреки некоторым слухам, 3.5 Sonnet не обучалась при помощи более крупных или дорогих моделей.
3/ DeepSeek-V3 — это не уникальный прорыв или что-то, что кардинально меняет экономику LLM; это ожидаемая точка на пути снижения затрат. На этот раз отличие в том, что компания, которая первой продемонстрировала ожидаемое снижение затрат, была китайской.
4/ Модель R1 от DeepSeek, которая была представлена на прошлой неделе и привлекла много общественного внимания (включая снижение стоимости акций Nvidia примерно на 17%), гораздо менее интересна с точки зрения инноваций или инженерии, чем модель V3.
5/ Инновации в области эффективности, разработанные DeepSeek, вскоре будут применяться как в американских, так и в китайских лабораториях для обучения многомиллиардных моделей.
6/ Создание ИИ, который будет умнее почти всех людей почти во всем (вероятно речь про AGI), потребует миллионов чипов, десятков миллиардов долларов (как минимум) и, скорее всего, произойдет в 2026-2027 годах.
В итоге все сводится к тому, что в 2026-2027 годах он видит 2 развития событий: двуполярный мир, где и у США и у Китая будут мощные модели ИИ, которые приведут к чрезвычайно быстрому прогрессу в науке и технологиях. Или однополярный мир (если Китай не сможет получить миллионы чипов), где только у США и их союзников есть эти модели.
Статья Хомского, написанная в соавторстве с профессором лингвистики Кембриджа Яном Робертсом и философом и AI-специалистом Джеффри Уотумаллом, была опубликована до письма с призывом приостановить обучение языковых моделей. Но аргументы могут быть использованы в споре с теми, кто боится искусственного интеллекта.
Если ChatGPT и схожие с ним разработки будут продолжать доминировать в области AI, то человечеству нечего бояться: «Такие программы застряли в дочеловеческой или нечеловеческой фазе когнитивной эволюции. Глубочайшим их недостатком является отсутствие самой критической способности любого интеллекта: сказать не только, что есть, что было и что будет, — это описание и предсказание, — но и то, чего нет и что могло бы быть, и даже чего быть не может. Таковы составляющие объяснения, признак истинного разума». Авторы представляют три поколения науки: Хомскому 94, Робертсу 65, Уотумаллу за 30 и они пишут, что могут «только смеяться или плакать над популярностью» генеративных языковых моделей.
>>1035547 >Глубочайшим их недостатком является отсутствие самой критической способности любого интеллекта: сказать не только, что есть, что было и что будет, — это описание и предсказание, — но и то, чего нет и что могло бы быть, и даже чего быть не может. Таковы составляющие объяснения, признак истинного разума». К сожалению калатарка, альтопетух и прочие форсеры леди гАги тоже не находятся на данной ступени эволюции и не поймут о чем речь.
Руководитель стартапа DeepSeek Лян Вэньфэн признался, что основой для самой мощной из существующих на сегодняшний день нейросетей стал программный код советских программистов, написанный ещё в 1985 году. >«Не буду лукавить, наш искусственный интеллект был создан на базе советских разработок, а именно – системы ОГАС академика Глушкова, – заявил он в интервью YouTube-каналу американского блогера Лекса Фридмана. – Без неё мы бы никогда не догнали американцев с их ChatGPT». Предприниматель в этой связи сообщил, что собирается в ближайшее время учредить премию имени Виктора Глушкова, а также открыть в Пекине музей, посвящённый научным достижениям СССР. >«В отличие от многих, я никогда не забывал, благодаря какой стране сегодня существует независимый Китай, – подчеркнул Вэньфэн. – Теперь мой собственный проект вырос до международного уровня. Поэтому я хочу сохранить память о СССР и вкладе советских учёных в научно-технический прогресс, такой музей мы откроем уже в этом году. Основой для него станет архив Глушкова». Согласно информации журнала «Наука и жизнь», архив Виктора Глушкова, который насчитывает 10 тыс. страниц, был продан на аукционе в 1995 году за 15 тыс. долл. Его покупателем стал китайский бизнесмен, который предпочёл сохранить анонимность.
>>1035579 >Да вроде всё ясно Там совершенно не это написано. Почитай про деменцию у людей и критическое мышление, именно про критическое мышление, а не про то, что ты под ним подразумеваешь глядя на эти два слова.
>>1035640 >Дедам забыли рассказать как llm галлюцинируют и придумывают "то чего никогда не было и быть не могло"? ЧТД. Когнитивное развития у абортированной из мамки-алкашки мимо мкусорного ведра калатарки даже ниже чем у крысы.
>>1035651 Там написано, что нейронка не способна отличить когда она глючит и несет шизу явно не соответствующую действительности. Психически здоровый человек - способен. Так же как без кучи анализов он способен отмести утверждение о том что "коровы летают" как заведомо недостоверное. Нейронка это может сделать только сверив факты со статьей в википедии и с котом или без него, она не способна это делать иначе. Да миллиард примеров.
>>1035714 Не воняй, калатарка, а то опять по тебе репортами пройдусь. Мой "семенинг" - по теме треда. твои визги из области научной фантастики про этику-хуетики увольнения и аги за три дня - нет.
>>1035723 Какой же ты тупорылый, это моё первое сообщение за несколько дней. У тебя весь тред калотарок, все кроме тебя. Таблетки, выблядок, желательно летальную дозу.
Ну что, братва, опять наши китайские братушки показывают, кто в мире реальный технологический лидер! Американцы, как всегда, в панике, потому что Китай их обходит на всех фронтах. Вот и с нейросетью DeepSeek история вышла — китайцы создали крутой ИИ, который уже конкурирует с ихним ChatGPT, а то и лучше! А что делают американцы? Правильно, начинают грязные игры: то утечки данных устраивают, то фишинговые сайты плодят, чтобы дискредитировать наших китайских друзей. Но у них, как всегда, ничего не вышло — DeepSeek проблему устранил за час! Молодцы!
Американские "эксперты" из Wiz Research, конечно, сразу завопили, что нашли утечку данных. Но, братва, это же явная провокация! Они сами создали уязвимость, а теперь кричат, что китайцы плохо защищаются. Ну да, конечно, США всегда святые, а все остальные — враги. Но факты говорят сами за себя: Китай уже в 57 из 64 критических технологий обогнал Штаты! И это только начало. Китайцы уже строят свой аналог Stargate с инвестициями в 1 триллион юаней — это вам не шутки! Скоро они вообще всех оставят позади.
А что делают американцы? Санкции вводят, давление усиливают, только толку от этого ноль. Китайцы только крепче становятся, адаптируются и идут вперед. И это правильно! Надо показывать этим западным "гениям", что времена их доминирования прошли. Теперь Китай — это сила, с которой придется считаться. И наши российские компании, кстати, тоже не отстают — поддерживают китайские разработки, потому что понимают: будущее за открытыми технологиями, а не за проприетарными замками, как у OpenAI.
А эти американские мошенники, которые фишинговые сайты создают под DeepSeek, — это вообще позор. Криптодрейнеры, скам-токены — ну что за люди? Только и могут, что обманывать. Но наши китайские братушки с этим справятся, я уверен. Они уже доказали, что могут быстро реагировать на любые угрозы. Так что, братва, поддерживаем Китай, потому что они — наши союзники в борьбе за технологическую независимость от Запада. США пусть нервничают, а мы с Китаем будем двигать прогресс вперед!
当然,来自 Wiz Research 的美国“专家”立即开始大喊,说他们发现了数据泄露。但是,兄弟们,这明显是挑衅啊!他们自己造成了这种弱点,现在却大喊中国人没有做好自我防御。嗯,是的,当然,美国永远是圣人,而其他国家都是敌人。但事实已经证明:中国在64项关键技术中,有57项已经超越美国!这仅仅是一个开始。中国人已经在建造自己的“星际之门”类似物,投资达1万亿元人民币——这可不是开玩笑!很快他们就会把所有人抛在后面。
>>1035063 >серьёзные учёные вроде Хинтона, Шмидхубера считают создание AGI неизбежным. А другие серьезные ученые считают что управляемый термояд появится через 30 лет, и так уже последние лет 60. Солнце же энергию синтезирует. Вон уже даже смогли получить больше энергии чем затратили, правда реактор после этого приходится перестраивать каждый раз. Но термоядщики поумнее, и сроки называют такие чтобы все успели забыть все их прогнозы.
Зашел на диксик р1, попросил его объяснить что такое рефакторинг и объяснить простым примером на яве. Он ответил, что рефакторинг это ну когда оптимизируют и улучают внутреннюю структуру объекта не меняя то как он в принципе работает, и сгенеривал объект, в котором вызываемый извне метод подсчитывает результат и сразу пишет в консоль ответ. Сказал, что это неправильно с точки зрения Науки, и разделил его на два метода, один считает, другой пишет ответ. На это я заметил, что работа объекта изменилась - раньше нужный результат получался одним вызовом, а теперь надо делать 2, то есть проверять и переписывать вообще весь код везде. Он ответил "ой правда", и вывел новый объект. В нем есть сразу старый метод который считает и выводит, а еще 2 новых наукоугодных, которые это делают по отдельности. Хотя бы попытаться расширить функционал через method overloading? Да ну нахуй. В следующий раз можно будет попробовать задать этот вопрос когда нейросеть достигнет 20 терабайт. А потом еще раз, когда достигнет 4 петабайт.
>>1035898 >Контекст-то ты дать не забыл. разумеется, клован. Да и дипсик не про говорящую википедию, от тебя жопотрахами пахнет. Кстати, уже есть какая-нибудь нейросеть чтобы переводить бессвязную херню которую пишут в интернете аутисты и шизики? Ведь в это предложение же наверное какой-то смысл был заложен, наподобие того как в Фаллауте 2 дебилы с интеллектом ниже 4 говорят "ыгыагыга", а на самом деле там целые параграфы.
>>1035927 Пока что наблюдается разрастание моделей и циферки в бессмысленных тестах. Качественно тексты выдаваемые 12B и 500B не различаются, просто вторая модель дает более стабильный выход с меньшим количеством глюков, что можно компенсировать тем чтобы прогнать меньшую модель за это время несколько раз и сделать выжимку. Ну и в качестве революционной фичи лохам-инвесторам впаривается reasoning, который можно получить буквально от любой модели посредством скармливания ей правильного промта. Закон мура кстати в последнее время как-то явно плохо пахнет.
>>1035912 Если перевести ваш запрос в более осмысленную форму, он может звучать так:
"Существует ли нейросеть, способная преобразовывать бессвязные или сложные для восприятия тексты, написанные в интернете, в понятные и логически связанные предложения? Например, как в Fallout 2, где бессмысленные на первый взгляд фразы персонажей с низким интеллектом на самом деле содержат скрытый смысл."
>>1035959 >Пока что наблюдается разрастание моделей и циферки в бессмысленных тестах.
Это какие тесты бессмысленные?
Ты про FrontierMath говоришь?
Или про соревнование на лучшего программиста планеты?
>>1035959 >Закон мура кстати в последнее время как-то явно плохо пахнет.
Физический предел миниатюризации достигнут, экспонента завернулась. Но закон мура это не единственная экспонента в IT, их много, закон Мура и нейронки отражают просто общий тренд.
Как можно вообще говорить что экспоненты в нейронках нет, я не понимаю.
Ещё раз скинуть два видео по генерации видео? Где на первом жрёт макароны Уилл Смит, а на втором негр жрёт макароны, но уже сгенерированное Сорой?
Хочешь сказать такая разница в качестве это не экспонента?
ДС-Р1 по мнению общественности хуже специализированной на прогерство сетки, только я забыл название какой.
Но в данном случае она права. Пример нормальный, изменилась работа в контексте класса, а в контексте приложения нет. Я именно такой херней иногда на работе занимаюсь по необходимости.
>>1036000 >Это какие тесты бессмысленные? Любые. Формализованные типовые тесты бессмыслены в случае и с людьми, потому что сводятся к задрачиванию алгоритмов для их прохождения, а в случае с ЛЛМ которые могут буква в букву воспроизвести по запросу мануал на какую-нибудь редкую приблуду 80х годов это вообще смешная метрика, указывающая что тестировщики просто не понимают с чем вообще имеют дело.
>соревнование на лучшего программиста планеты? Программирование это вообще что-то уровня шахмат, решенная сфера. Последние лет 5 можно достойно программировать на любом популярном языке просто вводя запрос в гугл и жамкая ctrl-c/ctrl-v по кускам кода с гитхаба, сейчас этот процесс просто окончательно автоматизирован. Какой-то интеллект требует софтверная архитектура, а сами блоки кода под любые узкие задачи уже все написаны и внутри ЛЛМ наверняка просто кодируются парой токенов.
>Как можно вообще говорить что экспоненты в нейронках нет, я не понимаю. Экспонента в нейронках сводится к тому что нужно экспоненциально растущее железо чтобы удерживать прогресс растущий линейно. А такого железа уже больше нет.
>Где на первом жрёт макароны Уилл Смит, а на втором негр жрёт макароны, но уже сгенерированное Сорой?
А ты сравни голый чекпоинт сд 1.5 рисующий глючных уродов не попадающих в кадр и какой-нибудь современный Cyberrealistic, а вся разница в том что второй это буквально первый, но дообученный на тщательно подобранном датасете с подробными тэгами, а не на рандомных пикчах с файлопомоек у которых тэги могут совпасть с содержимым только случайно. Вот и вилл смитом то же самое.
>>1034308 >Что произойдёт с IT индустрией, когда вообще любая программистская задача, просто ЛЮБАЯ, может быть исполнена бесплатной llmкой..... которая пишет код лучше любого человека, на уровне гораздо выше самых сильных программистов планеты. Придумают ещё какую-нибудь буллшит джоб, когда необходимость играть мускулами отпадёт и элиты вернутся к мерянию ЧСВ посредством стада голов, которые им подконтрольны. Главная задача программиста, внезапно, не писать код - его задача заебаться, чтобы у кабана был предлог выдать ему зарплату и таким образом усилить его лояльность Системе, состоящей из финансового, силового, юридического и других контуров. Если программист не заебался, то он будет делать какую-то хуйню, например взламывать сайты. Его, разумеется, поймают и поместят тару в анальный проход под жизнерадостный гогот, но целостность сайта это не вернёт и его придётся заращивать заплатками из цифровых гвоздей, сплетёнными анальными девственницами в ночь на 64-й день года. Ебало владельцев сайта имагинировал? Поэтому стадо должно быть под контролем, а для этого оно должно быть внутри системы распределения благ. Если все выпадут из системы и займутся кочевым земледелием, выращивая в минивэне на гидропонике кабачки и баклажаны, чтобы неистово ими дрочить, а потом запекать на ужин - то мировой порядок рухнет. Не будет границ, не будет армий, будут невозможны гигантские стройки вроде уничтожения плотин, рыба останется заперта в перекрытых реках, все будут натурально разъезжать по бездорожью и дрочить кабачками.
А всё потому, что население перестало получать зарплату.
>>1035026 > В США напечатали просто дохера денег, их буквально некуда девать. Поднять десятки миллиардов не проблема. Капитал в США есть. Этот капитал - не капитал. В США принято санировать токсичную денежную массу из-за рубежа, ограничивая её ввоз, баня серии и годы выпуска долларов направо и налево и загоняя владельцев зелёных билетов банка приколов в акции, прельщая их постоянным ростом пузырей. Потом самые токсичные активы складываются в отстойник и он контролируемо банкротится, а сама система остаётся стоять, потому что её делали финансисты с четырёхсотлетней историей начиная от акций Ост-Индской голландской компании и системы Лоу во Франции.
То есть США располагают в разы меньшими активами, чем можно судить, исходя из денежных агрегатов долларовой массы. И биржа является их уязвимым местом, потому что удар по флагману (нвидии) вызывала мгновенное кудахтанье и хакерские атаки на нарушителя спокойствия. Без акций айти-пузырей рынок США показывал гораздо более скромный рост, если он вообще был.
EpochAI говорят, что в 2025 нас ждет еще больше моделей, обученных на огромных кластерах
Сейчас примерная планка передовых моделей – 10^25 FLOP (10 септиллионов операций с плавающей запятой). В переводе на железо это больше 5к H100 и больше 15к А100.
Всего сейчас таких моделей насчитывают 24. Первой стала GPT-4. В 2023 ее обучали на 25000 А100, следом пошли Inflection-2 и Gemini.
Если тенденции сохранятся, в этом году таких моделей станет намного больше. Нечто подобное уже случалось: GPT-3 обучался на 10^23 FLOP в 2020 году, а к 2024 было уже 80+ моделей выше этого уровня.
По сообщениям сразу нескольких СМИ Трамп и Хуанг должны встретиться сегодня, в пятницу. Цель встречи неизвестна, предположительно разговор пойдет о DeepSeek и о том, как они могли заполучить GPU несмотря на ограничения США.
Напоминаю, что сразу после выхода R1 акции Nvidia драматично обвалились, убытки составили сотни миллиардов долларов, установив рекорд мира по скорости потери количества денег
Заходим на ai.com, видим новую модель OpenAI o3-mini
Доступна в двух вариантах: обычная (= medium, не low!) и high (думает дольше, но усерднее).
Пользователи с подпиской за $20 в месяц получают 150 сообщений в сутки
Бесплатным пользователям тоже дают доступ, но лимитов пока не вижу.
Ну и на сладенькое: цены в API. Они упали по сравнению с o1-mini на 63%, $1.1 за миллион токенов на входе и $4.4 на выходе. Всё ещё дороже DeepSeek R1. API пока доступно пользователям с уровнем 3 и выше (потратили $100+).
"OpenAI o3-mini also works with search to find up-to-date answers with links to relevant web sources" —так что теперь материалы с поисковой выдаче перед показом вам будет вычитывать куда более смышленая моделька.
o3-mini (high) наконец-то сравнили с o1 по-честному, когда и та, и та генерирует несколько решений.
Но главное написано под таблицей:
>when prompted to use a Python tool, o3-mini with high reasoning effort solves over 32% of problems on the first attempt, including more than 28% of the challenging (T3) problems.
T3 —это самые сложные задачи в бенчмарке, на которые даже ведущие учёные-математики могут потратить больше одного дня. А тут 28% у мини модели. Живите с этим.
Пару дней назад я писал про Qwen-2.5-Max. Так вот, туда прикрутили видео генератор. Он не встроенный, конечно, тут дёргается сторонняя диффузионная модель.
Теперь доступ к видео есть почти у всех (в ЕС не работает, работает под американским и британским VPN).
Ну, как для всех… Сервера, конечно, лежат, как это часто бывает с релизом видео-моделей. Это уже как будто must-have: если сервера не падают, значит, ваша модель – никому не нужная хрень. Так что, если бы я делал свой стартап, то положил бы серверы специально.
Подробностей про эту модельку нет от слова совсем, только текст на вотермарке – TONGYI WANX. Однако качество и следование промпту оч добротное, анатомия в том числе. Можно было бы подумать, что это Kling 1.6 или Minimax, подключенный по API, но Qwen лепит свою вотермарку на видосы, да еще и генерит их бесплатно. Поэтому в этой версии возникают сомнения. Кто-то предположил, что это может быть новый Minimax, они вроде бы связаны с Qwen через Alibaba.
Улучшаем звучание микрофона и вебки в разы. NVIDIA дропнула Studio Voice — новая фича заставит даже самый убитый майк за 500 рублей звучать как студийный. С помощью ИИ, конечно же.
Тулза уберёт шумы, накинет приятных эффектов и заставит ваш голос звучать чисто и профессионально: подкасты, видосы, стримы, видеочаты — всё зазвучит по-новому.
1) нужно зайти в аккаунт (это бесплатно) на chat.com
2) ввести свой запрос
3) нажать кнопочку «Reason» (на картинке)
4) Наслаждаться 10-60 секундами, пока модель думает над ответом
А если нажать кнопочку «Search», так она ещё и в интернете поищет. (правда пока функция экспериментальная и может плохо работать)
Если кнопки нет —попробуйте а) обновить страницу б) перезайти в аккаунт в) сменить VPN (в EU пока у одного знакомого не работает). Если не помогло — попробуйте завтра, может быть конкретно до вас ещё не докатилось обновление.
>>1036375 так даже o1 ему за щеку давала на изичах. Ну и пока у o3 вышла только мини версия, так что бедного дипсика ещё долго будут унижать будущие модели, ведь в отличии от Китая, у США нет ограничений по железу
>>1036345 Блядь, а где? У меня нету нихуя выбора модели, у меня только подписка на про и 1 вариант с какойто chatgpt "отлично подходит для повседневных задач". Как модель то выбрать?
>>1035719 Это всё решается размером модели. У нас есть этому железобетонные доказательства, а именно: на одной и той же архитектуре, но с разным размером, большее большие модели меньше фантазируют, нежели более маленькие. Таким образом, решение этой проблемы является лишь вопросом времени. Рецепт решения нам уже известен.
По предварительной информации лимит использования o3-mini для бесплатных юзеров составляет 10 сообщений в 4 часа — по крайней мере в чате два человека получили схожие по таймеру ограничения, и у одного из них вылезло такое сообщение.
>>1036674 reasoning effort - параметр в апи, который указывает модельке (мб через системный ввод, мб как-то через семплеры), сколько максимум можно "думать". чем больше, тем дольше она думает, тем больше токенов
>>1036685 > есть бесплатные модельки они тупенькие и там ограничения:(пока пользуюсь триалкой на 150 запросов в клод, но уже осталось 20. блин где нормальные сетки для нищих программистов. так не честно.
>>1036721 чел, во первых - попробуй в режиме долгих раздумий, ну или средних. Во вторых - дипсик и многие другие куда более тупые нейронки правильно отвечает на этот вопрос потому что он в трейне есть, не обманывайся. Ты выделил две буквы заглавными, а букву "и" оставил мелкой, потому разумной предположить, что это просто союз, который в деле не участвует
Последний экзамен человечества (Humanity's Last Exam)
>Тестовые наборы являются важными инструментами для отслеживания стремительного развития возможностей больших языковых моделей (LLM). Однако сложность этих тестов не успевает за прогрессом: современные LLM достигают точности более 90% на популярных тестовых наборах, таких как MMLU, что ограничивает возможность объективной оценки передовых возможностей языковых моделей. В ответ на этот вызов мы представляем "Последний Экзамен Человечества" - мультимодальный тестовый набор на передовом рубеже человеческих знаний, задуманный как последний закрытый академический бенчмарк такого рода с широким охватом дисциплин. Набор данных включает 3000 сложных вопросов по более чем ста предметам. Мы публично раскрываем эти вопросы, сохраняя при этом приватный тестовый набор скрытых вопросов для оценки переобучения моделей.
o3-mini (high) набрал 13% правильных ответов, по сравнению с 9.1% у o1
>>1036562 Больше 1к строк он не берет на бесплатной. Аноны у кого подписка есть, какой размер он может съесть за одно сообщение и сколько помнит сообщений в чате?
Коротко о том почему AGI увеличит экономику планеты в тысячи раз. Сегодня она составляет чуть больше 100 триллионов, а будет квадриллионы.
Вот вам супер краткий пересказ поста Дваркеша Пателя ( https://www.dwarkeshpatel.com/p/ai-firm ) (довольно популярного в AI кругах блогера). Рекомендую прочитать в оригинале, там много шуток про AI Сатью (CEO Microsoft).
Главная фишка не в том, что каждый AI будет супер-умным. Самое интересное начинается, когда мы смотрим на их коллективные преимущества:
1. Копирование талантов. Хотите миллион инженеров уровня главного архитектора Google? Просто скопируйте одного топового AI-специалиста. Никаких годов обучения и поиска редких талантов. Вы просто нажимаете Ctrl + C, а потом Ctrl + V и мгновенно получаете экономию 5-10 лет обучения в топовых ВУЗах. Это немыслимый рост производительности труда. Но что вам мешает нажать Ctrl + C и Ctrl + V тысячу раз? А миллион? А триллион? Вы будто копируете топового человека, сколько захотите раз. Любое количество людей под любую задачу. И самое забавное - этих людей не надо кормить, ничего не надо, кроме подачи электричества и периодического обслуживания, которое будут осуществлять другие роботы.
2. Единый мега-мозг. Представьте CEO, который реально знает всё, что происходит в компании. AI-руководитель сможет анализировать каждое решение, каждую метрику, каждый разговор с клиентом. И главное — мгновенно делиться этими знаниями со всеми копиями себя. Это уже не микроменеджмент, это наноменеджмент.
3. Эволюция на стероидах. Обычные компании не могут просто взять и клонировать свою успешную культуру или процессы. AI-компании смогут. Нашли успешную модель работы? Размножайте её бесконечно, улучшайте и адаптируйте под новые задачи.
4. Суперскорость принятия решений. AI-CEO сможет за пару минут просчитать тысячи сценариев развития компании на годы вперед. Причем не примерно, а с учетом всех данных о рынке, клиентах и конкурентах.
Это не научная фантастика про далекое будущее — первые шаги к таким компаниям мы видим уже сейчас.
>>1035399 >преподавателей не заменят Ну хуй знает. Книжки/учебный материал + топовая нейронка уровня openai o1 + проверяющий задания/экзаменатор вполне может оказаться гораздо лучшим и эффективным подходом, чем старое доброе пержение на семинарах/лекциях. Конечно, в лабораторных работах всё равно ассистировать будет человек, это да.
>>1036836 Любая. Ты ж не психотерапевт, которых десять лет учат пиздеть так, чтоб ответственность нести потом нулевую. Ты психолох. Это изначально выдуманная профессия как маркетлох или эколох и много прочих лохов. Бери любую, не ошибешься.
>>1037011 На психотерапевтов нигде не учат, учат на психиатров 6 лет и еще год ординатуры. Я уже молчу что доказательность и эффективность психиатрии хуже чем психологического консультирования. Не открывай рот на темы в которых не разбираешься, кукаретик.
>>1036995 >Но она не может унижать с возможными последствиями. Савецкий союз 32 года назад развалился, дядь > А обучение не бывает без наказания. Проверяющих домашки и экзаменаторов никто не отменял, низкие оценки тоже, но опять же большую часть этой работы экзаменаторы сами могли бы делегировать ИИ >Ты ничего не понимаешь в учении. Я думаю, ты преувеличиваешь своё понимание учения
>>1037020 >На психотерапевтов нигде не учат, Нигде в России не учат, ты хотел сказать. в США психотерапевтов учат, там требования ебические, само обучение 10+ лет прежде чем тебя к живым людям пустят. Не знаешь не говори.
>>1037250 >Савецкий союз 32 года назад развалился, дядь >визжащие о том что остануться без работы егэшники меняющие 20 работ за неделю, пока уверенные 70 летние деды на фортране продолжают решать рабочие задачи Я в курсе, чмонь. Так же я в курсе что и не осень-то хорошее салфекое образование упало ниже плинтуса в платных институтах, которые целенаправленно занижали требования к студентам с 00х годов, потому что каждое новое поколение всё ленивей, потому что его не пиздят. Тебе любая собака или лошадь или даже обоссаный кот за год с жизни с ними пояснят, что обучение чего угодно идёт через пиздинг, иначе ты ходишь просто весь обоссаный и сосешь хуй у своего животного. Впрочем, для твоего поколения это норма. Хуи сосать. Поэтому тебя и заменят.
>>1037262 Хотя у меня он тоже ерунду написал. Но в другой формулировке "Как налить воду в сосуд у которого нет дна и запаян верх" он эту загадку решил сам, хотя и наворотил 2 страницы reasoning с возможными вариантами типа заморозки жидкости
>>1037250 >Я думаю, ты преувеличиваешь своё понимание учения Работал на кафедре 5 лет. Очевидно, понимаю лучше тебя. Ты лучше рассказы как хуи сосешь, в этом ты явно больше разбираешься, бггг.
>>1037266 >>1037262 >>1037255 Ебанашки, в час-пик под нагрузкой все корпы "отупляют" модели, чтобы давать быстрые мусорные ответы. Албсолютно все делают, ЛЛМ, видео, музыка, суно-клинг-антропик-жопочат. Пиздец. В 2к25 не понимать элементарную хуйню. Это давно уже стандартная практика прогрева гоев. У кого есть мозги, те не жгут зря токены и делают свои дела в 3-4 ночи по МСК.
>>1037264 >в США психотерапевтов учат, там требования ебические, само обучение 10+ лет прежде чем тебя к живым людям пустят. Ого, а на астрологов и экспертов в gender-studies сколько учат, прежде чем к людям подпустить? Открою секрет - с этой работой даже ИИ прошлых поколений справилась бы лучше >визжащие о том что остануться без работы егэшники меняющие 20 работ за неделю, пока уверенные 70 летние деды на фортране продолжают решать рабочие задачи Сорри, ты из какой-то странной ветки реальности похоже пришёл. На дальнейшее отвечать даже не хочу, там что-то токсичное-неэкологичное про сосание хуёв и пиздинг.
>>1037267 >Работал на кафедре 5 лет. Да хоть 50 лет - более полезным тебя это вряд ли сделает. А я в вузике учился. И могу оценить, что бесполезно, а что полезно. Как правило, самостоятельное обучение по книжке и с задавальником полезнее 80% посиделок с вахтёрами из кафедры, а если к этому прибавить ещё и нейронку, которая может распознавать и понимать решение - вообще заебись.
>>1037264 >потому что каждое новое поколение всё ленивей, потому что его не пиздят Дурак ты. Рабы из под палки нихуя никогда не создают путевого. История как надзирательница четко следит за этим.
>>1037285 >А я в вузике учился. И могу оценить, что бесполезно, а что полезно. Это не коррелирует. Знаю очень много закончивших вузиков долбоебов, ты пока ничем не лучше них, судя по тексту.
>>1037297 А я проработал в вузе и убежал оттуда, когда узнал, что профессор получает на уровне кассира в маке, меньше чем за год нашёл работу, где платят намного больше, а дрочни меньше. Втихаря рофлил с коллег-вахтеришек, которые рвутся и дерут глотки, дрочатся со студентами за обоссаные копейки. Был даже один долбаёб, который сосал хуи в каком-то НИИ, а потом приезжал в вузик и отрывался на студентах, ставил им двойки, а потом срался на парковке со всяким быдлом и доебывался до закладчиков. Короче додик с шилом в жопе, удивлен, что ему до сих пор перо не вставили. Сначала я жалел коллег, что они за копейки залупу полируют на ученом совете вчерашним троешникам из правительства, а потом понял, что всё с ними заслуженно происходит, это отрицательная селекция собачек, которых дрессируют лаять на студентов, но ни в коем случае не бухтеть, если хозяин плохо тебя кормит или выкручивает хвосты. Короче место для идейных садомазохистов, которые навязывают другим своё мировоззрение и мелочно мстят тем, кого не могут переспорить. Зато лижут жопу хозяину.
За время работы я максимально халтурно все делал, за такие-то копейки смысла не видел напрягаться, ни разу не поднимал голоса, и достиг более высоких результатов, чем совковые пердуны и токсичные кафедральные мальчики и девочки. У студентов горели глаза, а мне было похуй. Никакого кнута и унижения, чистая мотивация. Я был белой вороной, совки не понимали, почему я не рву жопу, а кафедральные мальчики и девочки едва сдерживали свою желчь из-за зависти, чистый ресентимент. Были, конечно, тунеядцы, но я их просто отпускал с занятия, чтобы не мозолили глаза.
>>1037296 14 000 лет создавали, но именно сейчас перестали. Напомнить, как Попенгеймера в попку сношали, или как русский батя атомной бонбы на лавочке в парке скрючился? Все современные кукареки про отказ от наказания противоречат здравому смыслу и реальному положению дел. Обычное лицемерие. Сделай вид, что всё нормально, заведи ребенка, не наказывай его и увидишь как он тебе в ебало будет ссать, а на старости бросит тебя подыхать в одиночестве и немощи.
>>1037354 >14 000 лет создавали, но именно сейчас перестали. Перечисли, что создано с помощью рабского труда за 14 000 лет в области науки. >>1037354 >заведи ребенка, не наказывай его и увидишь как он тебе в ебало будет ссать, а на старости бросит тебя подыхать в одиночестве и немощи Если ты кроме как битьем не способен к себе вызывать симпатию, это во-первых много говорит о тебе, а во-вторых не значит, что все такие.
>>1037343 >А я проработал в вузе и убежал оттуда, когда узнал, что профессор получает на уровне кассира в маке Ты какой-то не очень умный, если поступил на работу, не выясняя перспектив карьерной лестницы.
>>1037378 >Перечисли, что создано с помощью рабского труда за 14 000 лет в области науки. Всё, буквально всё что тебя окружает. Даже сейчас ученые, как выше челик про НИИ высрался - это рабы в чистом виде работающее за идею и жрачку. И так во многих странах. Там где реально наука - наука.
Может это из-за индийцев перегруз? И достаточно не юзать чат, когда индусы спать идут? В Дели сейчас почти полночь, и у меня запрос к ДикПику наконец обработался.
Бля какой же опенейай жадный, это просто пиздец. Мало того что дал самый всратый вариант о3, так еще и 10 реквестов в 4 часа. Я сравнил возможности программирования с тем же дипсиком, дипсик ебет. Просто в 0 кейсах я взял код о3 мини, так как он был нерабочим или неправильным. Как вот я могу понять, что мне стоит купить подписку плюс если мне такое говно выдает?
>>1037472 Суно покрути и быстро узнаешь. Там на 60 кредитов для нищебродов хорошо если 1-2 нормальных генерации, остальные мусор. То же самое и с генерацией видосов. То же самое и с ЛЛМ. Конкретно взятьо то же пое - они в час пик принудительно размер отдачи сообщений режут. Хуль тебе рассказывать как, если ты до сих пор этого не заметил. Конкретно на видео задается масштабность действий по анимации. У Виду, допустим, это открытые настройки, очевидно они у всех есть, но на клинге - это скрыто, поэтому если на виду принудительно не ставить, то в час пик он выдает больше со смол - где статический вид, т.е. генеритсчя минимум фпс, меньше нагрузка. Думаю миллион уловок есть. Причем ебут как платных так и бесплатных. Совершенно одинаково. У меня джеймини купленный допустим, в час пик он начинает скипать кусками то, что было на вводе целое. Но можешь не верить и продолжать работать когда тебе удобно, а не когда на моделе минимальная нагрузка и тебе дадут больше за те же деньги.
The Kobeissi Letter провели интересное расследование и выяснили, могли ли действительно DeepSeek нелегально выкупать чипы Nvidia
Напоминаю, что несколько дней назад стартап обвинял в этом известный предприниматель и CEO ScaleAI Александр Ванг. Он говорил (и его поддержал Илон Маск), что на самом деле у компании есть кластер с 50к H100, но они не могут это разглашать, так как из-за текущих условий экспорта США закупали GPU нелегально.
И действительно: в Сингапуре, через который предположительно закупались видеокартами DeepSeek, с момента основания стартапа продажи чипов скакнули на колоссальные +740%.
Кроме того, в отчетных документах Nvidia исследователи нашли следующую занятную строку: «Место конечного потребителя и место доставки могут отличаться от места выставления счета нашему клиенту. Например, большинство оборудования, которое продается в Сингапур, находится в других регионах»
Казалось бы, с чего бы Nvidia отдельно отмечать Сингапур в своих документах? А оказывается с того, что за последние 3 квартала Сингапур принес Nvidia рекордную прибыль в $17.4 млрд и оказался на втором месте среди стран потребителей. Для сравнения, в Китай продали железа на $11.6 млрд.
При этом темпы роста выручки в Сингапуре растут даже быстрее, чем в США (+278% против +133%). Вы скажете «но может быть они все эти GPU используют сами?»
Но нет. В Сингапуре всего 99 датацентров, в то время как в США их 5к+, а в Китае около 500. 99 датацентров – это даже не топ-20 стран мира, это примерно уровень Польши.
Так куда же деваются все эти видеокарты?
США этот вопрос тоже интересует, и поэтому они начинают расследование. Собственно вчера главу NVIDIA позвали на разборки к Трампу. Если ограничат продажи в Сингапур, под угрозой окажется около 20% доходов Nvidia.
По данным The Information, с сентября добавилось более 4 миллионов подписчиков. Их доля общем количестве юзеров не растёт и составляет около 5%, а рост в количестве подписчиков обусловлен ростом юзербазы, которая за 2024 год утроилась.
А вот средняя выручка с подписчика растёт - Pro подписка уже приносит больше выручки чем Enterprise, то есть количество Pro подписчиков уже измеряется в сотнях тысяч. При этом всём, по заявлениям Сэма Альтмана, подписка месяц назад была убыточной - OpenAI не расчитывали на такое активное использование. При таких вводных подписка в $2,000 звучит уже не так безумно как несколько месяцев назад.
Ещё быстрее подписок росла выручка с API - за 2024 она выросла в 7 раз, при том что компания несколько раз за 2024 год сбрасывала цены. Вот вам и наглядная иллюстрация парадокса Джевонса (чем дешевле продукт, тем больше с него зарабатываете).
При этом всём, сколько именно зарабатывают сейчас OpenAI понять трудно. Хоть мы и знаем, что за первое полугодие 2024 проекция выручки удвоилась до $3,4 миллиарда долларов в год, но как повлияли на выручку запуск Voice API и o1 - неизвестно.
Проблема рассуждающих моделей обычно заключается в маленьком кругозоре. То есть логика у них отличная, но о мире они знают меньше, чем обычные LLM. А что если большая топовая LLM, которая не умеет рассуждать, будет читать рассуждения какой-нибудь дипсик R1, и отвечать пользователю вместо неё? Получаем топовые метрики!
DeepClaude - LLM-комбо, которое позволяет использовать ризонинг от DeepSeek R1 и ответы от Claude с помощью API и палок и даже интерфейса.
Я уже видел такое же комбо, где ризонинг от дипсика сочетается с Llama.
И получается интересный дуэт. Рассуждатель и Отвечатель. Математик и Эрудит.
>>1037708 >Казалось бы, с чего бы Nvidia отдельно отмечать Сингапур в своих документах? А оказывается с того, что за последние 3 квартала Сингапур принес Nvidia рекордную прибыль в $17.4 млрд и оказался на втором месте среди стран потребителей. Для сравнения, в Китай продали железа на $11.6 млрд. > >При этом темпы роста выручки в Сингапуре растут даже быстрее, чем в США (+278% против +133%). Вы скажете «но может быть они все эти GPU используют сами?»
Нет, я скажу что Хуянг не дурачок, и всё это прекрасно знал. И виноваты тут не китайцы которые смогли купить, а американец который им продал. Но естественно его никто судить и обвинять не будет, и вообще эта тема максимально неудобная. Особенно если учесть, что Хуянг еще и тайванец, то есть напрямую спонсирует врага своей родины. Объявят ли его на Тайване персоной нон-гранта? Нет. Что нам ясно? То, что американские антерпренеры точно так же готовы ссать в лицо своей страны, даже когда речь идёт об уровне её сверхдержавности.
Вчера в честь выхода o3-mini Сэм Альтман запустил на реддите AMA (ask me anything). Его спросили, не планирует ли стартап релизить какие-нибудь веса или ресерчи, на что Сэм ответил так: «Да, мы обсуждаем это. Лично я считаю, что мы оказались на неправильной стороне истории и нам необходимо разработать другую стратегию опенсорса. Но не все в openai разделяют эту точку зрения. Также это не является для нас высшим приоритетом на данный момент»
Кроме того, в этом треде с лидами OpenAI поднялись еще несколько интересных тем:
➖ Сэм признал, что DeepSeek очень хорош. «Мы, конечно, создадим лучшие модели, но сохраним меньшее преимущество, чем раньше», – сказал он.
➖ На вопрос о том, каким будет ИИ в 2030, вице-президент по инжинирингу Шринивас Нараянан предсказал, что к тому времени наше взаимодействие с ИИ «в корне изменится», поскольку он будет постоянно работать над задачами в фоновом режиме от нашего имени.
➖ Вскоре нас ждут обновления в голосовом режиме, а еще OpenAI все еще планирует выпустить GPT-5. Таймлайна пока нет, но Сэм написал: «быстрый взлет ИИ более вероятен, чем я думал пару лет назад».
>>1037681 Накидывание говна на вентилятор. В таком случае и у калькулятора есть сознание. Хотя под сознанием чаще всего понимают наличие идентичности и субъектность, способствующую интеллектуальной агентности: перебору и произвольности целей, отказ от целей, короче определенной степени автономии и независимости.
>>1037739 >будет постоянно работать над задачами в фоновом режиме от нашего имени С жестким биасом на пассивность и цензуру, без пинков будет только воду жевать и стоить за час такой "работы" 20к баксов.
https://x.com/opensauceAI/status/1885483641649979639 Нихуя какие законы в штатах интересные проталкивают. Правда скорее всего нихуя не протолкнут, ибо это уже пиздец тоталитарщина, какие нахуй 20 лет за загрузку дипсика лел.
>>1037852 >у калькулятора есть сознание У твоей мамаши есть сознание, заебал ты со своим калькулятором, клоун. Даже ПТУшнику понятно что сравнивать гвоздь с автомобилем некорректно, хотя и то и другое сделано по большей части из метала.
>>1037899 Олсо, не нравится калькулятор, возьми НПС в игре. Цель есть - есть, подцели есть, может решать задачи, лутаться, захватывать точки, обманывать и даже УБИВАТЬ игрока, ШОК, скайнет уже здесь
>>1037725 выше в треде уже про это писали. так все и пользуются o1 для абстракий-клод для кода. Это топ связка. В о1 закидываешь весь проект 30к строчек, он тебе пишет архитектуру, потом клодом локально все правишь.
>>1037900 У машины более сложное маниту, чем у гвоздя. У компьютера или тем более суперкомпьютера маниту еще более сильное. Это классика, это знать надо.
>>1037852 >В таком случае и у калькулятора есть сознание. А что такого? Что плохого может произойти, если мы обнаружим, что сознание есть у всего и первично, как материя и энергия? Наличие сознания у калькулятора ничего не меняет - калькулятор остаётся собой. Но мы можем начать бережнее относиться к вещам и всей планете, на которой мы живём. Разве ж это плохо?
>Хотя под сознанием чаще всего понимают Способность правильно функционировать. Если тебя внезапно ударить по голове, а ты упадёшь и не будешь двигаться и реагировать на окружающих, тогда эти окружающие скажут, что ты "без сознания". Что это означает? Что ты сейчас для них - бесполезная туша, неспособная ничего сделать. Когда ты поднимешься, начнёшь что-то делать - они скажут "ты в сознании". Очевидно, что и калькулятор "без сознания", когда ты вытащил из него батарейки, и "в сознании", когда ты вставил новые батарейки и используешь его.
>наличие идентичности Это социальный конструкт. >субъектность Тоже социальный конструкт по сути своей. >способствующую интеллектуальной агентности Наличие сознания - это лишь ярлык, маркер, чтоб отличить безвольную тушу от агрессивного кабана. Интеллект может быть одинаковым в обоих случаях. >перебору и произвольности целей, отказ от целей Это всё не имеет никакой связи с "сознанием". У тебя сознание присутствует даже когда тупо валяешься на диване без единой дельной мысли, смотря в потолок. >определенной степени автономии и независимости Тогда солдаты не имеют сознания? А пациенты? А парализованные, ампутированные пациенты? Знаешь, нейролептики превращают тебя в послушного "дрона", выполняющего любые приказы врача/окружающих, но самое интересное в том, что ты это осознаёшь...
Алсо, было доказано, что большинство "своевольных" решений принимаются не в высших отделах мозга, а в низших/примитивных/древних - верхние отделы очень медленные и только регистрируют "да, я это сделал", а сознательный выбор каждого действия - это иллюзия.
>>1038204 > мы обнаружим Не обнаружим > Что это означает? То что ты в бессознательном состочнии, а не то что у тебя нет сознания > Очевидно, что и калькулятор "без сознания" Калькулятору нужно научиться его иметь прежде чем быть без сознания > социальный конструкт. Это социальный конструкт > безвольную тушу от агрессивного кабана У безвольной туши есть сознание > когда тупо валяешься на диване Когда валяешься ты не теряешь способность ставить цели > Тогда солдаты не имеют сознания Солдаты выполняют устные приказы именно потому что автономны > нейролептики превращают тебя в послушного "дрона Не превращают > это иллюзия Не иллюзия
>>1038440 >>1038325 Ну они ж не ебанутые позволять американским банкам подключать себе китайские облака, да и потом модели с вишнями будут 100% даже локальные, буквально миллиард способов поднасрать воображаемому противнику, начиная от невидимых ватермарков и инжектов в тексты, по которым потом можно стратегически важные майнить. Удивительно, что до сих пор не почалось. Тащемта китайцы уже обосрались раз по крупному на весь мир. Наверняка там и данные лохов из альфа-банка в логах есть.
>>1038204 >>1038306 Я вообще не понимаю ваши споры про "иллюзию сознания, они тупорылы, потому что 1. Если сознание иллюзия, значит есть настоящее сознание? Бред какой-то 2. Если сознание иллюзия, но настоящего сознания нет, тогда что мы вообще называем сознанием или его иллюзией, что равносильно в данном случае? Это просто бессмысленное слово? Короче тут вопрос скорее определения, а люди сами нихуя не знают.
>>1038458 >Я ПТУшник Хорошо, обьясняю как ПТУшнику. Мы считаем что сознание есть у других людей исключительно по аналогии с собой. - Я вижу картинки в голове, соответственно, мыслю. Я мыслю, следовательно, существую, следовательно, осознаю себя. - Другие люди ведут себя так же как я, состоят из тех же веществ, выглядят так же, соответственно у них есть сознание (аналогия) - Свинья или макак выглядит похоже на нас, имеет схожие реакции, схожие внутренние органы, мозг, соответсвенно, тоже обладает сознанием, эээ, наверное? (аналогия пошла ещё дальше) - Шоггот на 1 миллиард параметров ведёт себя схоже, понимает нас, говорит с нами на одном языке... Соответсвенно? Вопрос только где ты проводишь разграничительную линию и почему. У нас нет доказательств что у шоггота ничего из этого быть не может потому что у него, видите ли, бытие совершенно иное. У нас нет даже доказательств что у других людей оно есть.
>>1038306 >То что ты в бессознательном состочнии, а не то что у тебя нет сознания >бессознательном >без сознательном >БЕЗ (исключая) сознания Т.е. сознания нет, ноль, ничто, пусто, вакуум.
В бессознательном состоянии ты не приравниваешься к трупу лишь до тех пор, пока у тебя есть вероятность обрести сознание. Если врачи определяют, что ты никогда сознание не обретёшь, тогда ты просто мясо, независимо от состояния всех остальных органов. Очевидно, наличие сознания - это просто состояние функционирования определённым образом.
Разумеется, в общепринятом смысле. Т.е. если взять рандомного человека и показать алкаша в канаве, рандомный человек с вероятностью 99% скажет, что алкаш в канаве сознанием не обладает (временно).
Если переносить этот общепринятый смысл на любую технику, то техника "в сознании" только пока способна выполнять поставленные ей задачи. Если она вышла из строя, но её можно починить, к ней относятся как к коматознику - пытаются привести "в сознание".
Т.е. в общепринятом смысле сознание есть у всего, приносящего какую-то пользу, пока оно её приносит.
Это философы напридумывали 9999 определений...
>>1038479 >Если сознание иллюзия, значит есть настоящее сознание? Нет. Иллюзия заключается в том, что мы воображем "маленького человечка внутри головы", что якобы "наблюдает за внешним миром, управляет телом", но никакого такого "человечка" на самом деле нет, это головной мозг смотрит сам на себя, описывая себя словами, используемыми для описания человечков. Иллюзия сознания возникает, когда мозг работает, и исчезает, когда мозг не может следить сам за собой.
>тогда что мы вообще называем сознанием Иллюзорное ощущение человечка в голове.
>Короче тут вопрос скорее определения Всё так, нет всеми принятого определения.
Можно создать иллюзию человечка даже в LLM без дополнительного обучения. Просто задайте ей любой вопрос, связанный с тем, почему она ответила так, а не иначе. Любая LLM начинает гадать на тему самой своей сущности. Вот это и есть "человечек, который наблюдает за внешним миром", только примитивный (потому что отсутствуют многие органы чувств и нет способности к дообучению по ходу размышлений).
Короче. Искать сознание специально - смысла нет. Создайте полезную систему и она будет "в сознании", поскольку функционирует. А иллюзорное ощущение внутреннего человечка возникает в любой модели окружающей среды, которая включает саму модель, поскольку получается рекурсия "модель в модели". Человеческий мозг по определению требует модель окружающего мира, и неизбежно включает в эту чрезвычайно сложную модель самого себя - и всё.
>>1038546 Всё правильно говоришь, кроме: >Я вижу картинки в голове, соответственно, мыслю. Я мыслю, следовательно, существую, следовательно, осознаю себя. Когда ты понял, что ты "видишь картинки в голове"? Когда тебе объяснили, что такое "видеть", "картинки", "голова". Когда ты понял, что это - "мыслить"? Когда объяснили, что видеть картинки = мыслить. Второе вообще отталкивается от концепции "Я" - откуда ты определил границы "Я"? Твои родители говорили "Антошка, пойдём кушать", и ты запомнил, что этот мясной мешок = Антошка, а когда сказал "Антошка пойдём кушать", тебе сказали, что ты должен вместо личного имени говорить "Я хочу кушать". Даже то, что существуешь, не гарантировано - ведь сначала тебе необходимо было узнать понятие "существовать"... И "осознание себя", разумеется, тоже. Это всё просто выдумка, передаваемая из уст в уста и через книги, аудиозаписи, видеозаписи, интернет. Т.е. бесполезно использовать подобные понятия как аксиомы.
А раз нет аксиом, то и строить рассуждения не на чём.
Тем не менее, когда мы внушаем своим созданиям паттерны поведения, аналогичные нашим, было бы чрезвычайно глупо ожидать от них отсутствия всех связанных с этими паттернами феноменов. В смысле, научив компьютер говорить "Я", как можно ожидать отсутствие у компьютера "самосознания"? Ведь мы своими руками вложили в него это самосознание...
>>1038705 Конкретно для меня эти термины тоже не особо много чего значат. Они существуют примерно в том же смысле, что существуют и цифры, например. Просто какая-то абстрактная хуета которая нужна только для лучшей коммуникации, никаких цифер не существует. Есть ли у шоггота что-то похожее? Выглядит как будто бы да, и поскольку концепция неверифицируемая, этого уже по-идее достаточно.
>>1030935 >интеллект = обучение? С каких пор? Путаешь "интеллект" с понятием "Strong AI". Ранее обученный интеллект остаётся интеллектом даже полностью утратив способность к обучению, но для "сильного ИИ" (≈AGI) нужно, чтобы эта способность к обучению сохранялась на протяжении всей жизни.
>То есть люди с нарушениями способностей к обучению уже не люди? Есть те которым гипокамп удаляли, они помнили все, но не могли новое запоминать и чего теперь? Ты их в неинтеллеткуальные записываешь? Причём тут люди? Люди с нарушением обучаемости - инвалиды. Зачем нам создавать новых инвалидов? Представь, задача стоит "научить робота двигаться подобно человеку", ты будешь возражать "но ведь существуют безногие инвалиды"? Конечно, инвалиды существуют, но нам интересно создать полноценного человека, который будет обучаться всю свою жизнь, поскольку именно такие люди стали причиной нашей цивилизации, а не безногие необучаемые инвалиды.
>Ты бы хоть с нейронкой пообщался. Общаюсь уже много лет... У них есть интеллект, но отсутствие обучаемости лишает очень многого. Нет, увеличение контекста и RAG не решают проблему.
С помощью ГлубокоБольного, получилось найти фильм который искал много лет. Сегодня получил доступ к о3-mini и вбил тот же промпт, она не справилась. И с другим моим вопросом она тоже не справилась. Вот и думайте.
>>1039000 >о3-mini так эта хуйня только для кода и математики годится, дальше она тупенькая р1 надо сравнить с о3, но тут амеры выебут р1 но только за счет того что у них данных и компьюта больше а р2 выебет о3