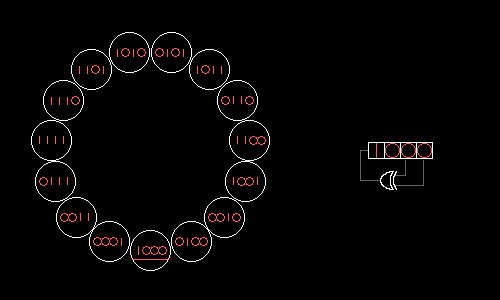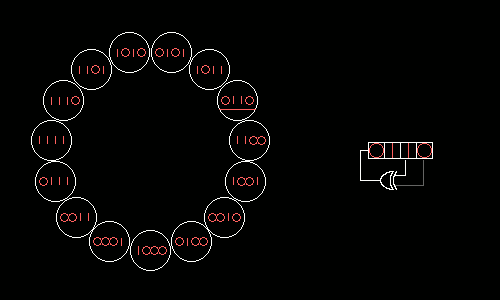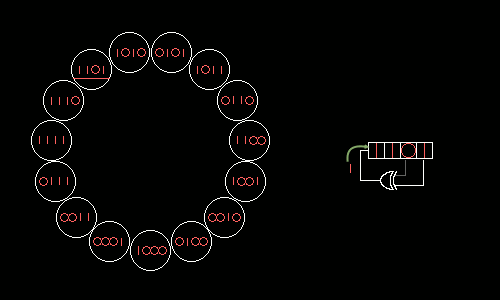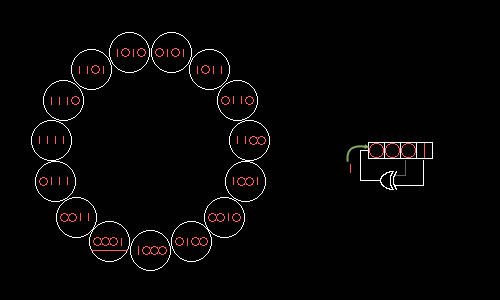
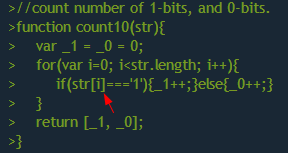
Кратчайшее представление натуральных чисел и способы разложения их.
Аноним
11/12/19 Срд 03:24:12
№
1